Golang的优势
由Google开发的语言,是一门编译型语言,编译出来的可执行文件(机器码)是单独的二进制文件,无需安装Go环境,不需要任何依赖(特殊情况除外)即可直接运行!!!
docker和k8s都是基于go编写的
极简单的部署方式
可直接编译成机器码
不依赖其它库
直接运行即可部署
静态类型语言(动态语言无编译器)
编译的时候可以检查出来隐藏的大多数问题
语言层面的并发
天生的基因支持
可以充分利用CPU多核
强大的标准库
runtime系统调度机制可以帮助做垃圾回收,资源调度等
高效的GC垃圾回收
- 用了三色标记、混合回收等
拥有丰富的标准库
简单易学
- 25个关键字
- 内嵌C语法支持
- 具有面向对象特征
- 跨平台
编译、执行时间对比

Golang基本语法
命令行
目前先掌握这些即可
go run:编译并运行go程序- 只能运行可执行程序(有
main()函数的程序)
- 只能运行可执行程序(有
go build:编译go程序,可针对任意包-o:后面跟输出文件名
go version:查看go版本go get path:从远程仓库下载G 模块或包到本地go env:查看环境变量
程序结构
Hello World
package main // 声明包
import "fmt" // 导入包
// 导多个包
import(
"fmt"
"time"
)
// 主函数
func main(){
fmt.Println("Hello World")
}包的声明
package main表明这是一个可执行程序(而不是库)- 只有包含
package main的程序才能编译为可执行文件 - 普通包编译后生成的是库文件(
.a文件) main包编译后生成的是可执行二进制文件
- 只有包含
- 包名通常与源文件所在目录的最后一级目录名一致
- 一个子文件夹内的所有源文件的package声明必须一致
包的导入
import导入了一个标准库fmt,这个包主要用于往屏幕输入输出字符串,格式化字符串import后面可以接一个括号,导入多个包import语句导入的是文件系统的目录路径,而不是包名
- 在
go中,大写开头的功能是可以公用的(公有),小写开头的功能只能在包里面使用(私有)- 功能包括函数、方法、变量等
- 导包的时候会先执行要导的包的
init()函数,形成层级调用
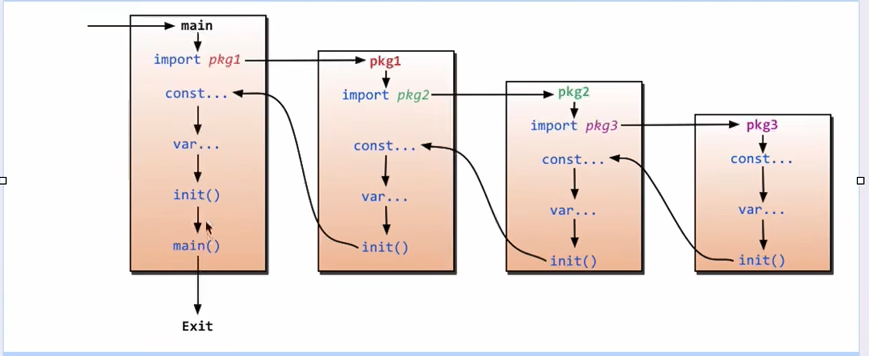
- 可以使用
_对已导入但不使用的包起别名,防止程序报错,但是会执行这个包的init()方法- 也可以在路径前指定别名
- 可以使用
.把导入的包里的方法全部引入,在当前源文件直接调用
package main
import(
_ "./lib1"
mylib2 "./lib2"
. "./lib3"
)
func main(){
// 用别名启用方法
mylib2.Lib2Test()
// 直接调用方法
Lib3Test()
}语法
- 函数的主左括号一定要和函数名同一行,否则编译不通过
常见API
fmt.Print():按顺序输出参数,但不会自动添加空格或换行fmt.Println():会在每个参数之间自动添加空格,并在结尾自动换行fmt.Printf():可以用%d、%s、%v等占位符来自定义输出,不会自动换行fmt.Sprint():拼接字符串并返回fmt.Sprintf():按照规则拼接字符串fmt.Sprintln():拼接并加空格 + 换行strconv.ParseInt:将字符串转换为整型,返回值为转换结果和错误信息s:要转换的字符串base:进制10:十进制(最常用)2:二进制8: 八进制16: 十六进制
bitSize:目标整数位数
strconv.Atoi:直接转成intmath.MaxInt64:有符号最大值math.MinInt64:有符号最小值变量一,变量二 = 变量二,变量一:变量交换time.Now():获取当前时间,返回类型为time.Time.AddDate(year,month,day):在当前日期进行日期变换.Formate():对日期进行格式化.Unix():转换成秒级时间戳
- Go内置了
Error接口,实现类的时候若有要求可以直接实现Error接口
排序
// 整数切片排序
sort.Ints(nums []int) // 升序
sort.IntsAreSorted(nums []int) bool // 检查是否已排序
sort.SearchInts(a []int, x int) int // 二分查找
// 浮点数切片排序
sort.Float64s(f []float64) // 升序
sort.Float64sAreSorted(f []float64) bool
// 字符串切片排序
sort.Strings(s []string) // 字典序
sort.StringsAreSorted(s []string) bool基本数据类型
// 布尔类型
bool
// 字符串类型
string
// 整数类型
int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
// uint8的别名,即一个字节
byte
// int32的别名,四个字节,表示一个Unicode字符,常用来表示单个字符
rune
// 浮点类型
float32 float64
// 复数类型
complex64 complex128
// 字符串类型,使用""或者``表示
string格式化
%v:默认格式%T:类型的字符串表示%t:布尔值,显示为 true 或 false%d:十进制整数%x:十六进制整数%b:二进制整数%c:对应的 Unicode 字符%s:字符串%q:双引号括起来的字符串,适合打印 JSON%p:指针的地址%f:浮点数%e:科学记数法的浮点数%g:根据数值大小选择%e或%f%#v:Go 语法表示的值%#x:带有前缀 0x 的十六进制整数
变量声明
四种变量的声明方式
func main(){
// 方式一
var a int
// 方式二
var b int = 100
// 声明多个变量
var b,c int = 1,2
var bb,cc = 100,"zxb"
var(
bbb int = 100
ccc string = "zxb"
)
// 方式三
var c = 100
// 方法四:省略var关键字
e := 100
}var
基本语法:
var 变量名 变量类型使用
var可以自动推导变量类型用
var声明的变量值默认值为0使用
fmt标准库的Printf方法打印数据类型- 打印数据类型:
fmt.Printf("type of a = %T",a),占位符用%T
- 打印数据类型:
可以声明全局变量
可以声明多个变量,可以进行多行的多变量声明(需要用括号括起来)
:=
- 使用
:=可以实现变量的声明和初始化 - 可以自动推导变量类型
- 无法在函数外使用,即无法声明全局变量
- 可以使用
:=快速重新赋值,而不是再声明一个
常量的定义
const(
BEIJING = 10*iota // iota=0
SHANGHAI // iota=1
SHENZHEN // iota=2
)
func main(){
const length int = 10
}const
- 具有只读属性,声明后不能再次修改
- 可以自动推断类型
- 可以声明全局变量,可以使用大括号声明多个变量
- 使用大括号声明的时候可以使用关键字
iota,每行的iota都会累加1,第一行的iota的值是0
- 使用大括号声明的时候可以使用关键字
函数
import "fmt"
// 示例
func fool1(a string,b int) int{
fmt.Println("a = ",a)
fmt.Println("b = ",b)
c := 100
return c
}
// 返回多个返回值
func fool1(a string,b int) (int,int){
return 666,777
}常见说明
go的函数支持多返回值- 声明函数返回类型需要用括号指定多个返回值的类型
- 函数的参数类型写在参数名后面,返回类型写在函数名后面
- 函数名推荐驼峰命名法
- 对于多个相同类型的参数,可以只写一个参数类型
- 可以使用
_对返回值进行忽略
带名称的返回值
- 函数值的返回值可以被命名
- 作用域为当前函数范围!!!
- 使用空的return语句直接返回已命名的返回值
func split(sum int) (x,y int){
x = sum*4/9
y = sum-x
return
}指针
和c语言的类似,在这给个例子看一下区别即可
- 接收指针类型参数的时候用
*声明,也用*进行地址的解引用 - 用
&获取变量的地址
package main
import "fmt"
func add(n int) {
n += 2
}
func addptr(n *int){
// 此时n里面存的是p的地址
*n += 2
}
func main(){
p := 5
add(p)
fmt.Println(p) // p = 5
addptr(&p)
fmt.Println(p) // p = 7
}异常
在 Go 中的异常有三种级别:
error:正常的流程出错,需要处理,直接忽略掉不处理程序也不会崩溃panic:很严重的问题,程序应该在处理完问题后立即退出fatal:非常致命的问题,程序应该立即退出
panic和recover
- 可以使用
panic抛出异常,异常会逐层向上传播,如果没有recover,程序会崩溃 - 可以使用
recover捕获异常
func checkTemperature(temp float64) {
// defer 函数会在 checkTemperature 返回前执行,无论是因为正常 return 还是因为 panic
defer func() {
// 在函数结束前检查是否有 panic
if r := recover(); r != nil {
fmt.Println("\"体温异常\"")
}
}()
if temp > 37.5 {
panic("体温异常") // 触发异常
}
// 函数正常结束
}error
本身是一个预定义的接口,该接口方法下只有一个方法Error(),该方法的返回值是字符串,用于输出类型信息
type error interface {
Error() string
}创建error
- 使用
errors包下的New函数
err := errors.New("这是一个错误")- 是使用
fmt包下的Errorf函数,可以得到一个格式化参数的 error
err := fmt.Errorf("这是%d个格式化参数的的错误", 1)错误传递
- 使用
wrapError进行包装- 实现了
error接口,用于返回当前当前层的错误 - 拥有
Unwrap方法,用于返回被包装的下层错误
- 实现了
type wrapError struct{
msg string
err error
}
func (e *wrapError) Error() string {
return e.msg
}
func (e *wrapError) Unwrap() error {
return e.err
}wrapError不对外暴露,需要使用fmt.Errorf()进行创建- 创建时必须使用
%w对错误进行格式化,且参数只能是一个有效的err
- 创建时必须使用
err := errors.New("错误")
wrapErr := fmt.Errorf("错误,%w",err)处理
- 使用
errors.Is方法判断错误链中是否包含指定的错误
func Is(err, target error) boolerrors.Unwrap()函数用于解包一个错误链
panic
**注意:**当程序中存在多个协程时,只要任一协程发生panic,如果不将其捕获的话,整个程序都会崩溃
创建
- 使用内置函数
panic,签名如下- 当输出错误的堆栈信息时,
v也会被输出
- 当输出错误的堆栈信息时,
func panic(v any)善后
- 使用
defer进行出现panic后的善后工作,这里不细说
恢复
- 使用
recover函数进行及时的处理并且保证程序继续运行,且必须要在defer里运行
func main() {
dangerOp()
fmt.Println("程序正常退出")
}
func dangerOp() {
defer func() {
if err := recover(); err != nil {
fmt.Println(err)
fmt.Println("panic恢复")
}
}()
panic("发生panic")
}条件判断
if后面必须要有大括号,且不能把if语句写到同一行if-else判断语句没有小括号- 允许在判断条件之前执行一个简单的语句,用
;隔开,一般用于声明临时变量 else一定要跟在if大括号后面- 使用
else if而不是elif
// 不合法
if v > 10 work()
if v > 10{ work() }
// 合法
if v > 10{
work()
}
if st:=0 ;v > 10{
st = 1
work()
}else{
// ...
}switch语句
switch语句后面不需要括号switch的case可以判断多个值switch里面的每个分支结尾自带break- 可以用
fallthrough关键字强制进入下一个case - 若
switch 变量,则case后面必须写与变量匹配的值
switch{
case t < 12:
fmt.Println("")
default:
fmt.Println("")
}循环
go只有for循环continue和break和其它语言的功能一样
for{
这是一个死循环
}
for j:=7;j < 9;j++{
continue
break
}
i:=1
for i<=3{
++i
}defer语句
- defer后面必须是函数调用语句
- defer后面跟的函数会在外层函数返回之前触发
- 有多个defer的时候会按顺序入栈,外层函数返回之后会依次出栈
- defer是在return之前执行的
import "fmt"
func main(){
defer fmt.Println("world")
fmt.Println("hello")
}// 输出 hello world调用defer函数体
- 在最后加
(),是为了立刻调用这个defer函数
defer func(){
if r := recover(); r != nil{
msg = "体温异常"
}
}()Slice
切片,也就是动态数组(内存空间动态开辟)
静态数组
var 数组名 数组长度 数据类型 {数据}:定义数组,可以把数据的声明省略- 也可以用
:=定义
- 也可以用
var myArray1 [10]int
myArray2 := [10]intlen(数组名):获取数组长度
var myArray1 [10]int
for i:=1; i len(myArray1);i++{
fmt.Println(i)
}range:可以使用这个关键字迭代数组,获取index(索引)和value(值)_:如果不需要索引或者值,可以使用匿名变量_进行忽略
// 表示固定长度数组
var myArray1 [10]int
// 使用range迭代数组
for index,value := range myArray1{
fmt.Println("index = ",index,"value=",value)
}
// 使用匿名变量
for _,value := range myArray1{
fmt.Println("value=",value)
}对数组进行传参的时候,需要注意:
- 数组是值传递,在函数内部修改数组的时候只修改副本,原数组不变,且声明的形参的数组长度要和传入的数组长度一致
// 正确 func method(arr [5]int){ } // 错误 func method(arr [4]int){ } func main(){ arr := [5] int method(arr) }可以用
fmt.Println()打印数组
动态数组
- 声明切片:定义数组时不指定元素长度
- 声明切片并初始化
- 声明
nil切片,使用make关键字进行空间分配- 第一个参数为数组类型,第二个为元素个数
- 直接使用
make关键字声明 - 使用
:=和make声明
// 声明切片并初始化
slice1 := []int{1,2,3}
// 声明slice是一个切片,但是并没有给slice分配空间
var slice1 []int
slice1 = make([]int,3)
// 直接使用`make`关键字声明
var slice1 []int = make([]int,3)
// 使用:=和make声明
var slice1 := make([]int,3)- 传参时传递切片可以避免拷贝,因为切片是引用类型
// 避免拷贝
func modifySlice(s []int) {
s[0] = 100 // 修改会影响原数组
}
func main() {
a := []int{1, 2, 3, 4, 5} // 切片(非数组)
modifySlice(a)
fmt.Println(a[0]) // 输出 100
}nil切片:一个声明但未初始化的切片变量会自动设置为nil,长度和容量都为0
func main() {
var phone []int // nil类型切片
}- 切片的追加
- 使用
make关键字传参,定义合法元素数量和切片总空间 - 可以使用
append关键字进行切片扩容,增加合法元素数量,a = append(a,value)- 也可以使用
append进行切片对切片的追加 - 当切片总空间不足,底层会进行扩容,扩容一倍
append如果跟了多个独立切片,需要用...解包运算符
- 也可以使用
- 使用
// 声明切片
var numbers = make([]int,3,5)
// 扩容
numbers = append(numbers,1)- 从头部插入元素
nums = append([]int{-1, 0}, nums...)
fmt.Println(nums) // [-1 0 1 2 3 4 5 6 7 8 9 10]- 从中间下标i插入元素
nums = append(nums[:i+1], append([]int{999, 999}, nums[i+1:]...)...)
fmt.Println(nums) // i=3,[1 2 3 4 999 999 5 6 7 8 9 10]- 从尾部插入元素
nums = append(nums, 99, 100)
fmt.Println(nums) // [1 2 3 4 5 6 7 8 9 10 99 100]- 切片的截取
s[i:]:从i切到末尾s[:j]: 从开头切到j(不含j)- 子切片的底层是定义了一个新指针指向父切片的某个 位置作为子切片的起点,而不是拷贝
- 可以使用
copy()函数进行切片的拷贝copy(s1,s2):把s2中的值拷贝给s1
s := []int{1,2,3}
// s1的值为1,2
s1 = s[0:2]Map
声明Map类型
[]里面存的是key的类型,外卖放value的类型- 空间不够会自动扩容
- 使用
make方法开辟内存空间 - 使用
:=直接声明 - 声明的时候进行初始化
- 使用中括号插入键值对
可以使用
key和value直接赋值
// 声明map
var myMap1 map[string]string
// 开辟内存空间
myMap1 = make(map[string]string,10)
// 直接赋值
myMap1["one"] = "php"
myMap2["tow"] = 'js'
myMap3["three"] = "go"
// 直接声明
var myMap2 := make(map[int]string,10)
// 声明的时候初始化
myMap3 := map[string]string{
"one":"php",
"two":"js",
"three":"go"
}Map的操作
- **遍历:**使用
range关键字进行遍历
myMap3 := map[string]string{
"one":"php",
"two":"js",
"three":"go"
}
for key,value := range myMap3{
fmt.Println("key = ",key)
fmt.Println("value = ",value)
}- **删除:**使用
delete关键字进行删除- 第一个参数为map的变量名
- 第二个参数为要删除的键值对的
key
myMap3 := map[string]string{
"one":"php",
"two":"js",
"three":"go"
}
delete(myMap3,"one")- **修改:**直接根据
key进行修改
myMap3 := map[string][string]{
"one":"php",
"two":"js",
"three":"go"
}
myMap3["one"] = "python"- 直接进行传参的话,
map类型是引用传递
Struct
结构体声明
type Person struct{
Name string
Age int
}结构体初始化
- 使用
var关键字,不立刻进行初始化
var p person
p.name = "jhwang"
p.age = 20函数传参
- 结构体作为函数参数默认是值传递
- 引用传递需要传递结构体地址
// 值传递
func changeStruct(person Person){
// ...
}
func main(){
var p person
p.name = "jhwang"
p.age = 20
changeStruct(person)
}
// 引用传递
func changeStruct(person *Person){
// ...
}
func main(){
var p person
p.name = "jhwang"
p.age = 20
changeStruct(&person)
}结构体标签
- 定义结构体时还可以为字段指定一个标记信息
- 一个字段可以有多个标记信息,多个标记信息之间用空格隔开,标记信息为键值对形式,使用
``包裹
type resume struct{
Name string `info:name` `doc:我的名字`
Sex string `info:sex`
}封装
使用结构体来表示类
- 类名称首字母大小写都可以,大写则表示当前类公有
- 类的属性、方法大小写都可以,大写则表示当前类的属性、方法公有
直接初始化
- 使用
{}对变量名进行赋值并进行初始化
type Person struct{
Name string
Age int
}
person := Person{name: "Alice", age: 25}实现类方法
- 在方法名前使用
this作为接收者名称this可以看作是调用者别名- 默认是值传递
// 值传递
func (this Person) SayHello() {
fmt.Printf("Hello, my name is %s\n", this.name)
}
person.SayHello()
// 引用传递
func (this *Person) SayHello() {
fmt.Printf("Hello, my name is %s\n", this.name)
}
person.SayHello()继承
类的继承
- 在子类的结构体属性中加入父类名
- 可以直接对父类已有方法进行重写
type Human struct{
name string
sex string
}
func (this *Human) Eat(){
// ...
}
// 继承
type SuperMan struct{
Human // SuperMan继承了Human类的方法、属性
level int
}
// 重写父类方法
func (this *SuperMan) Eat(){
// ...
}多态
接口
使用
interface关键字声明本质上是一个指针
只要一个类实现了接口定义的所有方法,就自动实现了该接口
类实现了接口的方法和类的指针实现接口的方法是不同的
- 类实现了接口的方法,那么值类型和指针类型都可以赋值给接口
- 类的指针实现了接口的方法,那么只有指针类型可以赋值给接口
type Animal interface { Speak() } type Cat struct{} type Dog struct{} // 指针接收者实现方法 func (d *Dog) Speak() { fmt.Println("Woof") } // 值接收者实现方法 func (c Cat) Speak() { fmt.Println("Meow") } func main() { var a Animal // 值类型和指针类型均可赋值 a = Cat{} // 合法 a = &Cat{} // 也合法(Go 自动解引用) a = &Dog{} // 合法 a = Dog{} // 编译错误:Dog 未实现 Animal(缺少 *Dog 的方法)
interface{}(空接口)可以存储任意类型的值,是万能容器
type iface struct {
tab *itab // 类型信息
data unsafe.Pointer // 实际数据的指针
}多态
- 使用接口声明,实现接口的类定义
- 可以定义一个方法,使用接口声明形参,实现了接口的类都可以调用这个方法
type AnimalIF interface{
Sleep()
GetColor() string
GetType() string
}
func ShowAnimal(animal AnimalIF){
// ...
}
// 实现接口的类
type Cat struct{
color string
}
// 实现接口
func (this *Cat) Sleep(){
// ...
}
func (this *Cat) GetColor() string{
// ...
}
func (this *Cat) GetType() string{
// ...
}
type Dog struct{
color string
}
func (this *Dog) Sleep(){
// ...
}
func (this *Dog) GetColor() string{
// ...
}
func (this *Dog) GetType() string{
// ...
}
func main(){
// 声明接口
var animal AnimalIF
// 实现多态
animal = &Cat{"green"}
animal.Sleep()
fmt.Println(animal.GetColor())
fmt.Println(animal.GetType())
// 实现多态
animal = &Dog{"blue"}
animal.Sleep()
fmt.Println(animal.GetColor())
fmt.Println(animal.GetType())
}通用万能类型
- 使用空接口来表示通用万能类型
- 类型断言:使用
x.(T)判断x是不是和T的类型一样- 检查接口变量的动态类型是否满足目标接口,即如果
T是接口类型,断言检查x的动态类型是否满足T接口(x是否实现接口T) - 变量名一定要是空接口类型
- 返回
value和ok- 类型相同
ok为true,value为变量名的值
- 类型相同
- 检查接口变量的动态类型是否满足目标接口,即如果
// 使用空接口来表示通用万能类型
func MyFunc(arg interface{}){
// ...
// 使用类型断言
value,ok = arg.(string)
}
type book struct{
// ...
}
func main(){
book := Book{}
// 函数能够正确识别book类型
MyFunc(book)
}反射
变量构造(pair)
Go中的每个变量,在底层都是一个(type,value)对
- 变量类型:
type- 静态类型:
static type,声明时就能确定的类型 - 具体类型:
concrete type,运行时才能确定的类型
- 静态类型:
- 变量值:
value pair会连续不断地传递,且不会变化
var a string
a = "aceld"
var allType interface{}
// allType里面的value和type和a的一样
allType = a反射
用于接口interface
需要导入
reflect库使用
ValueOf()返回传入的数据的值使用
TypeOf()返回传入的数据的类型
对于简单和复杂数据类型都可以使用
对于复杂数据类型
- 先获得输入类型
- 使用
.NumField()方法获得参数个数 - 使用
.Field()方法获得参数类型 - 使用
.Field().Interface()方法获得参数值 - 使用
.NumMethod()方法获得方法个数 - 使用
.Method()方法获得方法信息
func reflectNum(arg interface{}){
fmt.Println("Type=",reflect.Typeof(arg))
fmt.Println("Value=",reflect.Valueof(arg))
}
func main(){
var num float64 = 3.14
reflectNum(num)
}
// 反射
func DoFiledAndMethod(input interface{}) {
// 获取类型信息
inputType := reflect.TypeOf(input)
fmt.Println("inputType is :", inputType.Name())
// 获取值信息
inputValue := reflect.ValueOf(input)
fmt.Println("inputValue is:", inputValue)
// 遍历字段
for i := 0; i < inputType.NumField(); i++ {
field := inputType.Field(i) // 获取字段定义信息
value := inputValue.Field(i).Interface() // 获取字段实际值
fmt.Printf("%s:%v=%v\n", field.Name, field.Type, value)
}
// 遍历方法
for i := 0; i < inputType.NumMethod(); i++ {
m := inputType.Method(i)
fmt.Printf("%s:%v\n", m.Name, m.Type)
}
}反射获取结构体标签
- 使用
.Field().Tag.Get("标签的key")获得字段标签 .Elem()方法用于获取指针、数组、切片、映射、通道或接口所指向的元素的类型.Kind()方法用于获取一个值的底层类型种类- 可以统一处理所有类型的数据,如
reflect.Int8、reflect.Bool等
- 可以统一处理所有类型的数据,如
type resume struct{
Name string `info:name` `doc:我的名字`
Sex string `info:sex`
}
func findTag(str interface{}){
t := reflect.TypeOf(str).Elem()
for i:=0 ;i < t.NumField();i++{
taginfo = t.Field(i).Tag.Get("info")
tagdoc = t.Field(i).Tag.Get("doc")
}
}结构体标签
将结构体标签转换为json格式
导入包:
encoding/json定义结构体标签
key固定为jsonvalue为json格式的key
使用
json.Marshal()方法传入结构体转换成json字符串- 返回
json字符串和错误码 - 发生错误时错误码不为空
- 返回
使用
json.Unmarshal()方法把json字符串转换为结构体- 需要传入结构体地址和
json字符串 - 返回错误码
- 需要传入结构体地址和
import "encoding/json"
type Movie struct{
Title string `json:"title"`
Year int `json:"year"`
}
func main(){
movie := Movie{"喜剧之王",2000}
jsonStr,err = json.Marshal(movie)
movie := Movie{}
err = json.Unmarshal(jsonStr,&movie)
}goroutine(协程)
多线程多进程操作系统
- 解决了阻塞问题,线程A阻塞,CPU可以切换到线程B
- 但是CPU利用率不高
- CPU需要在每个线程之间进行切换,切换成本高
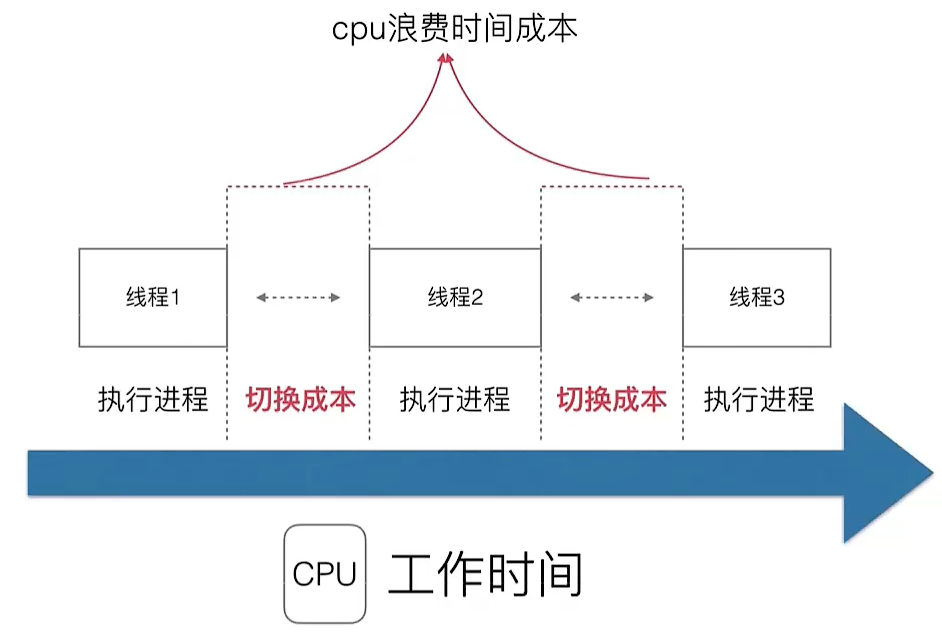
因此协程应运而生
goroutine与系统线程的区别
goroutine创建与销毁的开销较小goroutine的调度发生在用户态(轻量级的线程),切换成本低;系统线程的调度发生在内核态,切换成本高goroutine的通信可通过**channel完成,系统线程通信依赖共享内存和锁机制**
协程的调度模型
N:M模型- N个操作系统的线程通过协程调度器和M个协程进行通信
- N个线程是操作系统调度的实体,M个协程是用户态任务
- 协程调度器负责在M个协程之间切换,但它们运行在N个线程上
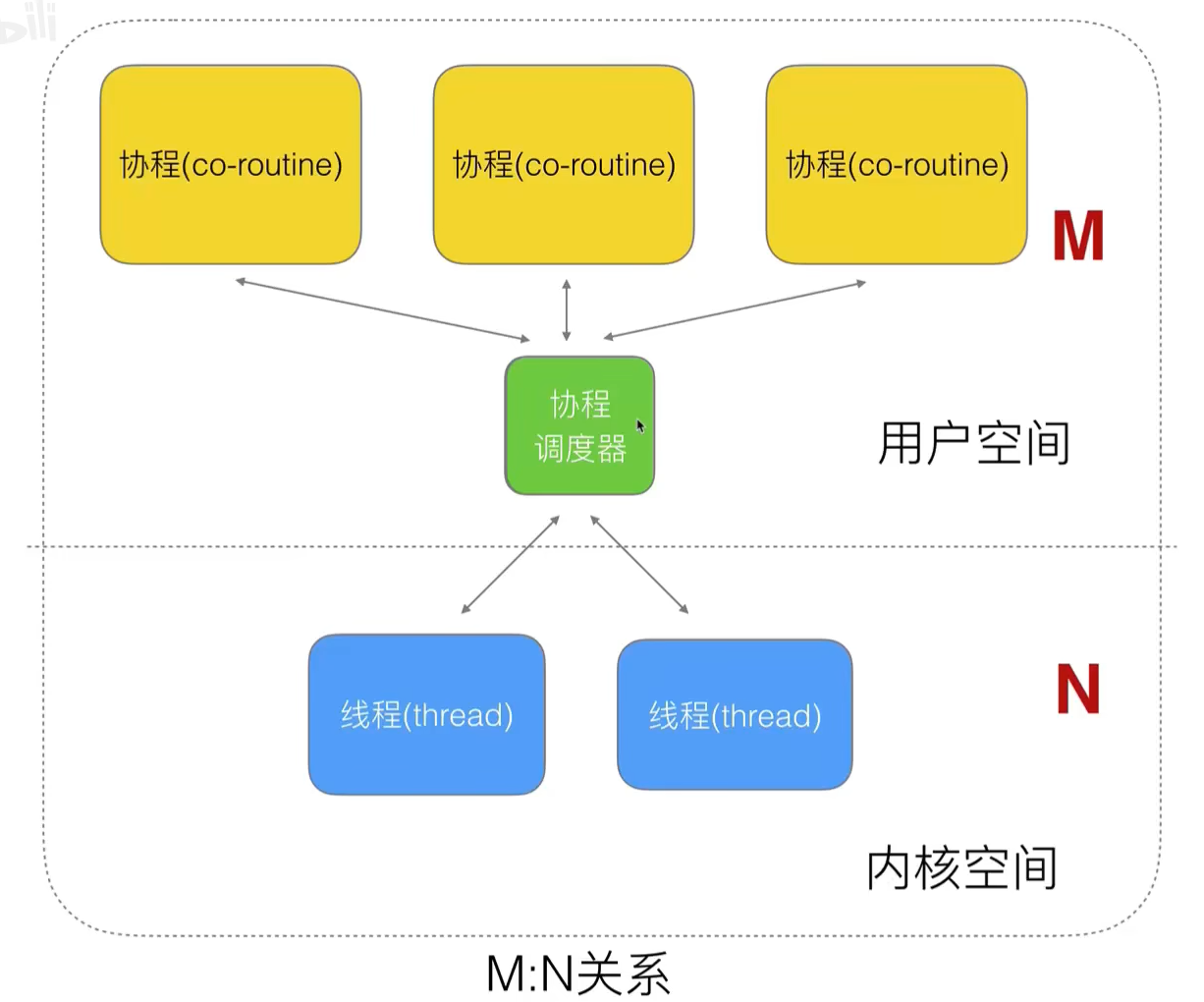
创建goroutine
在方法前加go关键字
main方法是主goroutine,自定义方法是从goroutinemain方法退出时其它从goroutine会死亡
func newTask(){
i := 0
for{
i++
fmt.Printf("Hello")
}
}
func main(){
go newTask()
}- 直接创建
go协程并执行- 创建形参为空,返回值为空的匿名函数
- 匿名函数需要在代码后面加上
(),告诉编译器立即执行 - 在代码后加上括号,不填形参
- 在
go协程里面再创建匿名函数,可以使用runtime.Goexit()方法退出当前goroutine
- 匿名函数需要在代码后面加上
- 创建形参不为空,返回值不为空的匿名函数
- 在代码后加上括号,填入形参
- 返回值需要通过
channel拿到
- 创建形参为空,返回值为空的匿名函数
func main(){
// 1.
go func() {
defer fmt.Println("A.defer")
func() {
defer fmt.Println("B.defer")
runtime.Goexit() // 退出当前goroutine
fmt.Println("B") // 这行不会执行
}()
fmt.Println("A") // 这行不会执行
}()
// 2.
go func(a int, b int) bool {
fmt.Println("a =", a, ", b = ", b)
return true
}(10, 20)
for{
// ...
}
}Channel
常见类型
- 双向
channel
ch := make(chan int)- 只发送
channel
var out chan<- int- 只接收
channel
var in <- chan int常见方法
c:=make(chan int):创建channel,传递的数据类型是intchannel <- value:发送value到channel,默认传递引用<- channel:接收并丢弃x,ok := <-channel: 从channel读取数据并赋值给x,ok检查管道是否为已经关闭
func main(){
c := make(chan,int)
go func(){
c <- 666
}()
num := <- c
}num:= <- c和c <- 666是同步执行的,因此不能确定谁先谁后- 当
num:= <- c先执行时,对应的thread会进行阻塞,等待666的传入 - 当
c <- 666先执行时,要把666写入到channel,但是channel无缓冲,因此对应的thread也会进行阻塞,直到执行num:= <- c
- 当
无缓冲的channel和有缓冲的channel
无缓冲
- 传数据的
goroutine必须等待拿数据的goroutine把手伸进来,否则阻塞
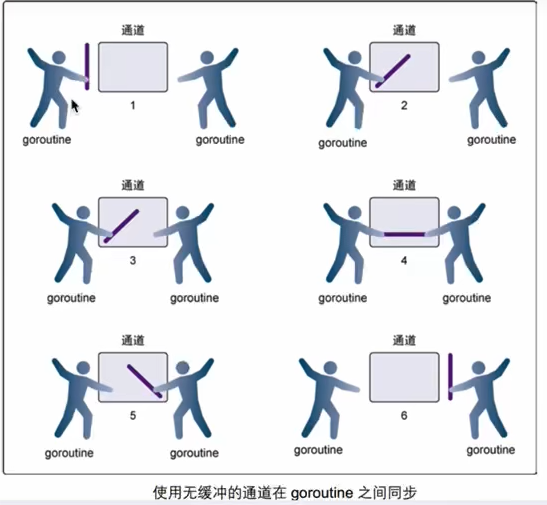
有缓冲
- 传数据的
goroutine只需要把数据放到通道,读数据的goroutine只需要从通道拿数据 - 当通道空了或者通道满了,协程才会阻塞
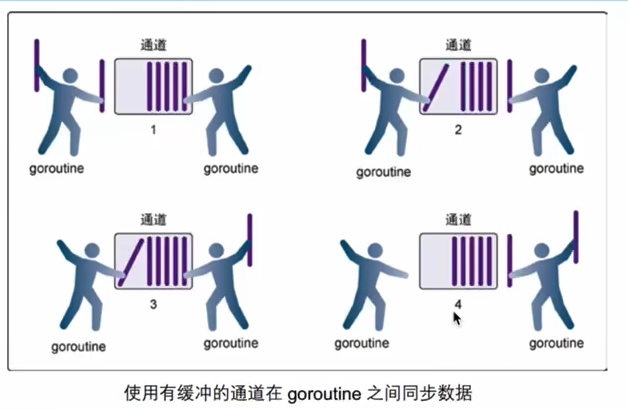
创建有缓冲的channel
- 使用
make(chan,int,3)方法创建通道,3表示通道容量- 使用
len(c)获取通道元素数量 - 使用
cap(c)获取通道容量
- 使用
func main(){
c := make(chan,int,3)
}channel的关闭特点
- 使用
close(chan)可以关闭一个协程 x,ok := <-channel: 从channel读取数据并赋值给x,ok检查管道是否为已经关闭- 确认已经没有数据发送之后,要把channel进行关闭,否则读取数据的协程会发生死锁
- 注意:对于有缓冲channel,关闭channel之后仍然可以从channel中接收数据
channel和range
- 使用
range关键字从管道获取数据
c := make(chan,int,3)
for data := range c{
fmt.Println(data)
}channel和select
在同一协程下监控多个
channel使用
select定义多个case,哪个case先触发就会用哪个case的处理语句
select{
case <- chan1:
// 如果channel1读取到数据,就执行此case处理语句
case chan2 <- 1:
// 如果成功向channel2写入数据,就执行此case处理语句
default:
// 如果以上都没有成功,进入default处理流程GoModules
是Go语言的依赖解决方案,解决了依赖管理问题
GoPath的弊端
- 没有版本控制概念
- 无法同步一致第三方版本号
- 无法指定当前项目引用的第三方版本号
go mod命令
go mod init:生成go.mod文件- 后面跟上模块名称
go mod download:下载go.mod文件中的所有依赖go mod tidy:整理现有的依赖go mod graph:查看所有的依赖结构go mod edit:编辑go.mod文件go:修改go版本-require:添加依赖-droprequire:移除依赖-replace:替换依赖-exclude:排除版本
go mod vendor:导出项目所有的以爱到vendor目录go mod verify:检查一个模块是否被篡改过
go mod环境变量
GO111MODULE:用来控制Go modules的开关auto:只要项目包含了go.mod文件的话就启用Go moduleson:启用Go modulesoff:禁用Go modules
可使用环境变量设置
go env -w GO111MODULE=onGOPROXY:设置Go模块的代理,在后续拉取模块版本时直接通过镜像站点拉取- 默认值为
https://proxy.golang.org,direct
- 默认值为
如:
go env -w GOPROXY=https://goproxy.cn.directGOSUMDB:拉取模块版本时检验代码是否经过篡改- 默认值为
sum.golang.org - 设置了
GOPROXY可以不用管这个
- 默认值为
GONOPROXY/GONOSUMDB/GOPRIVATE:用于管理私有模块行为的关键配置,即不走代理、不进行校验和检查- 直接使用
GOPRIVATE,它的值会作为GONOSUMDB和GONOPROXY的默认值 - 可以设置多个模块,多个模块以英文逗号分隔
- 直接使用
go.mod文件
module github.com/yourname/project // 模块路径(必填)
go 1.21 // 最低要求的 Go 版本(必填)
require ( // 直接依赖列表
github.com/gin-gonic/gin v1.9.1
golang.org/x/sync v0.3.0
)
replace ( // 替换依赖源(可选)
golang.org/x/sync => ./local/sync // 本地替换
)
exclude ( // 排除特定版本(可选)
github.com/old/lib v1.2.3
)
retract ( // 撤回发布的版本(可选)
v1.0.0 // 严重漏洞
)go.sum文件
- 罗列当前项目直接或间接的依赖所有模块的版本,保证今后项目依赖的版本不会被篡改
- 会生成一个哈希值用来进行校验
其它补充知识点
time
三件套
time.Time:某个具体时刻time.Duration:时间长度,纳秒为单位的int64time.Location:时区
固定模板
// 秒级
2006-01-02 15:04:05
// 毫秒级
2006-01-02 15:04:05.000
// 天
2006-01-02
// 小时
2006-01-02 15
// 分钟
2006-01-02 15:04
// ISO8601,带时区
time.RFC3339常用方法
// 获取当前时间
now := time.Now()
// 进行格式化
now := time.Now().Format("2006-01-02")
// 加减时间间隔
now := time.Now().Add(time.Duration)
// 按年月日添加
now := time.Now().AddDate(year,month,day)
// 加载时区并对时间t进行转换
loc, _ := time.LoadLocation("Asia/Shanghai")
tLocal := t.In(loc)
// 获取时间戳
tsSec := time.Now().Unix() // 秒
tsMs := time.Now().UnixMilli() // 毫秒
tsNs := time.Now().UnixNano() // 纳秒
// 时间戳转回Time
t := time.Unix(tsSec, 0) // 秒
t := time.UnixMilli(tsMs) // 毫秒
t := time.Unix(0, tsNs) // 纳秒
// 计算时间差
start := time.Now()
cost := time.Since(start) // 相当于time.Now().Sub(start)
// 分桶对齐到整点整分
t := time.Now().UTC()
hourStart := t.Truncate(time.Hour) // 对齐到整小时
minStart := t.Truncate(time.Minute) // 对齐到整分钟
// 时间先后判断
t.After(u) // t 在 u 之后
t.Before(u) // t 在 u 之前
// 取年月日
y, m, d := t.Date()
// 取时分秒
h, min, sec := t.Clock()
// 取星期
wd := t.Weekday()
// 解析字符串
t1, err := time.Parse("2006-01-02 15:04:05", s) // 默认按UTC解析
loc, _ := time.LoadLocation("Asia/Shanghai")
t2, err := time.ParseInLocation("2006-01-02 15:04:05", s, loc) // 按时区进行解析error
几个常见概念
error:GO内置的接口类型Error():error接口必须有的方法,返回的是字符串errors:标注库中的errors包errors.New():创建简单错误errors.Is(err,target):错误比较- 是进行指针比较,会沿着错误链去寻找
target,查看是否是同一个对象 - 支持自定义方法
- 是进行指针比较,会沿着错误链去寻找
errors.As(err,&target):错误的类型断言- 会沿着错误链去寻找
target,判断是不是同个类型 - 然后将
err的值赋给target
- 会沿着错误链去寻找
errors.Unwrap():解包错误
fmt.Errorf():用格式化字符串创建一个error%v:把错误进行字符串拼接,不形成错误链%w:对错误进行包裹,形成错误链
// 声明普通错误
err := fmt.Errorf("invalid id: %d", id)
// 对错误进行包裹
err := fmt.Errorf("read file failed: %w", err0)
// 把err0.Error()拼进字符串
err := fmt.Errorf("read file failed: %v", err0).Err():gorm框架中使用,可以调用这个方法拿到一个error
结构体标签
JSON
基本用法
type User struct {
ID int `json:"id"`
Name string `json:"name"`
}常用Tag
omitempty:空值就不输出,以下几种情况会被判定成空值- 数字0
- 空字符串
Falsenil
-:完全忽略字段,不参与JSONstring:整数、布尔转字符串
ID int `json:"id,string"`Binding
调用了ShouldBind方法校验就会生效
常用校验
required:必须存在且非零值omitempty:字段为空则跳过校验- 数值类
gt/lt:大于/小于某个值gte/lte:大于等于/小于等于某个值eq/ne:等于/不等于某个值oneof:枚举验证,值之间用空格隔开
email:满足邮箱格式uuid:满足uuid格式url:满足url格式- 字符串类
min:最小长度max:最大长度len:必须要为这个长度
Form
Query/表单参数绑定,主要用于
GET:?page=1&pageSize=10POST:表单提交
常常和binding配合使用,-表示忽略
uri
路径参数绑定,用于RESTful API
使用方法:uri:"param_name"
header
绑定HTTP请求头到结构体
常用的header绑定
Authorization:标准token入口,不会自动去掉BearerCookie:session/jwtX-API-Key:API-Key鉴权X-Request-Id:请求唯一IDUser-Agent:浏览器/客户端信息Referer:来源页面Origin:跨域来源X-Forwarded-For:反向代理转发的客户端IP,可能是列表X-Real-IP:客户端真实IPContent-Type:请求体类型
类型断言与类型转换
类型断言
从接口值把里面真实的具体类型拿出来
接口值(interface/any)包括了
- 动态类型,会随着装进去的值的变化而变化
- 动态值
语法:x.(T)
x必须是接口类型(interface或any或其它接口),判断它里面的动态类型是不是T两种方法
v := x.(T):失败会panicv,ok := x.(T):安全写法,转换失败ok为false
类型转换
把一个值变成另一种具体类型
语法:T(x)
x本身是具体类型,要转换成另一个具体类型
strings
一个处理字符串的包
常用方法
strings.Contains(s,substr):判断s是否包含子串substrstrings.HasPrefix(s,prefix)/strings.HasSuffix(s,suffix):判断前缀/后缀strings.Split(s,seq):用分隔符把字符串切成切片strings.Join(elems,seq):将切片用分隔符seq拼接成字符串strings.TrimSpace(s):去除首尾的空白字符strings.ToUpeer(s)/ToLower(s):大小写转换
注意
len(str)返回的是字符串的字节数,不是字符数
strings.Builder
特点:底层直接操作[]byte缓冲区,避免频繁内存分配和GC
比正常的+快
- 正常的
+,每次都会创建一个新的字符串对象,重新分配内存并拷贝数据,效率很低 strings.Builder底层维护一个[]byte,只有在需要扩容时才分配内存- 将
[]byte转换成string时,使用了**unsafe指针转换进行零拷贝**- 零拷贝:直接让
String指向Slice([]byte)现有的Data内存
- 零拷贝:直接让
常用方法
Builder.Grow(n):预先申请n个字节内存Builder.WriteString(s string):把字符串拼接到末尾Builder.WriteByte(c byte)/WriteRune(r rune):拼接单个字符Builder.String():将[]byte转换成stringBuilder.Reset():清空内容,长度置零,但保留已分配的内存
匿名字段
空结构体
struct{}
零内存占用
所有空结构体的值都是相等的,且共享同一内存地址
无字段,不能存储数据
make
创建切片
make([]T,length,capacity)
length为当前切片使用的大小,capacity为底层数组总大小
创建map
make(map[K]V, capacity)
capacity为容量,空间不够会扩容
创建通道
make(chan T, capacity)
- 无
capacity为无缓冲通道,否则为有缓冲通道 - 不会自动扩容