本页PDF
- 从高维正态分布采样,维度与生成图片的维度大小相同
- 模型对采样后的数据去除噪声,会连续经过去噪模型(次数事先定好),最后把噪声通通滤掉,得到图片
- Denoise模型除了会接受图片作为输入,还会接受一个数字作为参数,这个数字表示当前图片受噪声影响严重的程度,客观上反映了进行到哪个step
- Denoise模型内部的Noise Predicter对图片噪声进行预测,得到噪声图片,然后用原图片减去噪声图片得到更加清晰的图片
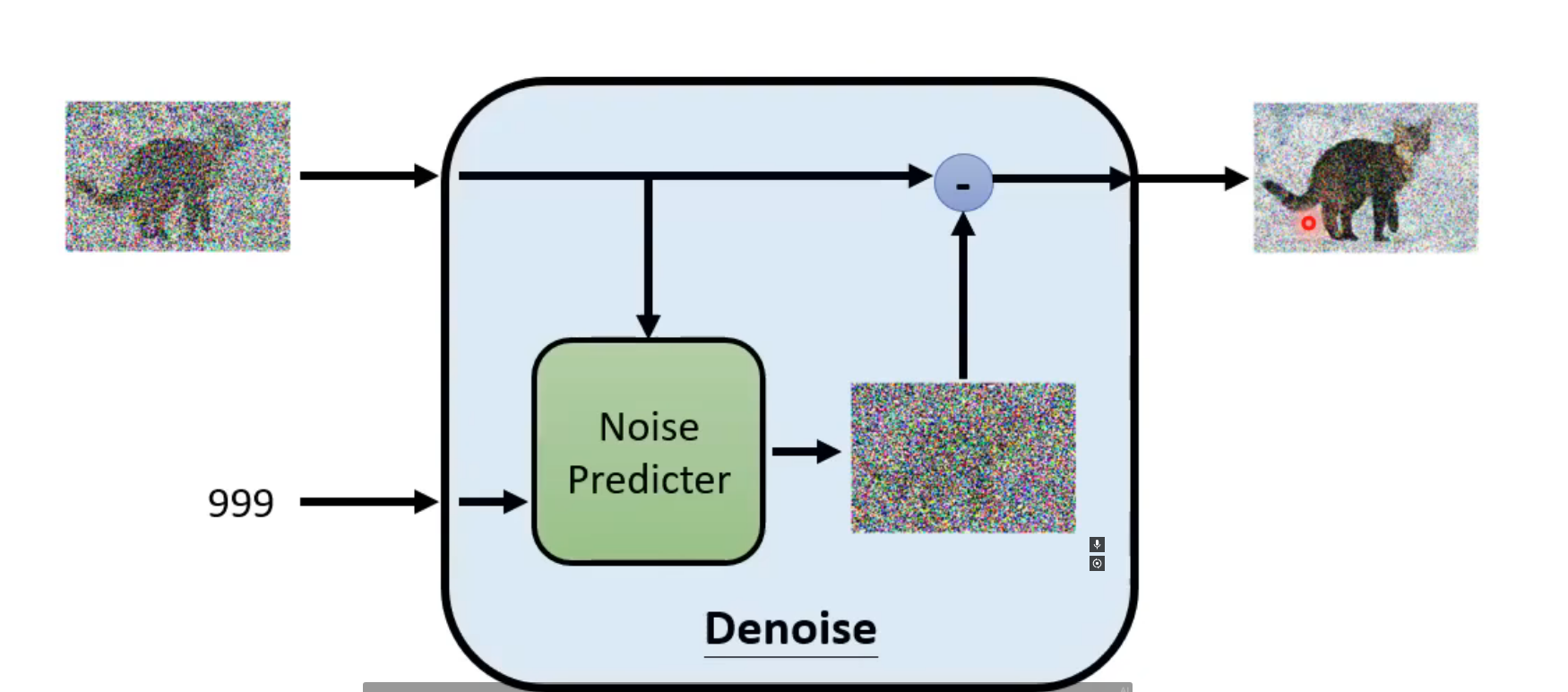 image-20250510233616851
image-20250510233616851可以看作是VAE的一个扩展,从左到右逐步编码,从右到左逐步解码
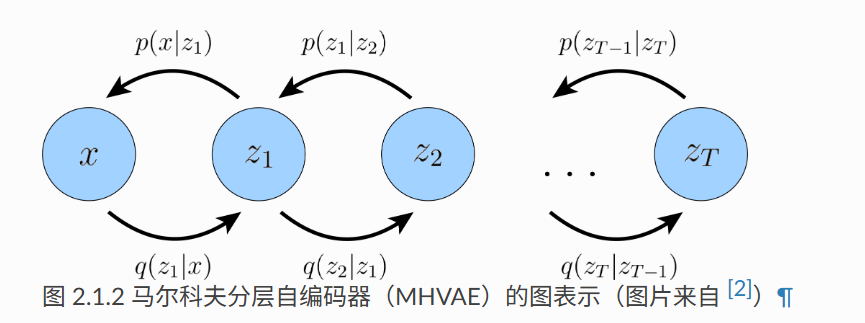 image-20250511132150467
image-20250511132150467q(zt∣zt−1)表示一个步骤的编码过程,p(zt∣zt−1)表示一个步骤的解码过程
整个模型的联合分布概率为
p(x,z1,z2,…,zT)=p(x,z1:T)=p(zT)pθ(x∣z1)t=2∏Tpθ(zt−1∣zt)
隐变量的Z1:T后验概率可以分解为
qϕ(z1,z2,…,zT∣x)=qϕ(z1:T∣x)=qϕ(z1∣x)t=2∏Tqϕ(zt∣zt−1)
我们希望学到的模型能尽可能生成与真实样本分布一致的数据,模型的优化目标是为了最大化p(x)
lnp(x)=ln∫p(x,z1:T)dz1:T=ln∫qϕ(z1:T∣x)p(x,z1:T)qϕ(z1:T∣x)dz1:T=lnEqϕ(z1:T∣x)(qϕ(z1:T∣x)p(x,z1:T))≥Eqϕ(z1:T∣x)(lnqϕ(z1:T∣x)p(x,z1:T))
前向编码过程的每一个步骤的编码器q(xt∣xt−1)不再通过神经网络学习,而是固定为一个高斯线性变换。
不区分x和z,每个xt的尺寸都是相同的
由于编码器被假设为线性高斯,当T趋向无穷时,xT是一个正态分布即随着T的增大,xT趋近于正态分布。这个线性高斯设定一个小于 1 的渐系数, 可以使得xT收敛到一个标准正态分布
两种方法算出来的值是不同的
描述数据从干净状态x0逐步加噪到xT的路径概率
p(x0:T)=q(x0)t=1∏Tq(xt∣xt−1)
描述从噪声xT逐步去噪生成$x_0 $路径概率
p(x0:T)=p(xT)t=T∏1p(xt−1∣xt)
代表真实图像x0的真实概率分布p(x0)的概率密度函数是不知道的,但我们能得到一批真实的图像样本,也就是我们有x0的观测样本, 此时x0是已知观测值,x1:T 是未知的隐变量, 这时整个马尔科夫网络的联合概率变成了一个条件概率q(x1:T∣x0)。
q(x1:T∣x0)=q(x0)q(x0:T)=q(x0)q(x0)∏t=1Tq(xt∣xt−1)=t=1∏Tq(xt∣xt−1)
根据前面的假设,前向过程每一个步骤的编码器q(xt∣xt−1)固定为一个线性高斯变换。定义 q(xt∣xt−1)的方差与xt−1 是独立的, 并且为βtI, 其中0<β1<β2<…βT<1 。这么做的意义:前期方差较小,添加的噪声少,扩散速度慢;随着方差逐步加大,添加的噪声越来越多,扩散的速度加快。βt是人工指定的。
定义q(xt∣xt−1)的均值μxt和xt−1是线性关系,这里设定另外一个系数αt,并且令αt=1−βt。μt与xt−1的关系定义为
- 这里是xt−1上的每一个像素点乘上一个αt得到每一个像素点的均值μxt
μxt=αtxt−1
xt的方差定义与xt−1无关,而是经过缩放的单位方差,定义为
Σxt=βtI=(1−αt)I
那么这个时候q(xt∣xt−1)就是一个以αtxt−1为均值,以(1−αt)I为方差的高斯分布(方差固定不变)。它可以看作是在αtxt−1的基础上加上一个N(0,(1−αt)I)的随机高斯噪声。这就相当于每一个步骤都在前一个步骤的基础上加上一个随机高斯噪声数据,随着t 的增加, xt逐步变成一个高斯噪声数据。
q(xt∣Xt−1)=N(αtxt−1,(1−αt)I)
xt=αtxt−1+N(0,(1−αt)I)=αtxt−1+1−αtϵ,ϵ∼N(0,I)
αt并非固定,可以随着t的增长逐渐变小。
总的来说,前向过程就是一个逐步添加高斯噪声,最终变成一个纯高斯噪声数据的过程,无参数化表示,假定是一个确定的线性高斯变换。
前向过程中可以从x0一步计算任意的t,这样可以并行计算全部的xt。公式中的ϵt是从一个标准正态分布中采样的。推导过程如下:
xt=αtxt−1+1−αtϵt=αt(αt−1xt−2+1−αt−1ϵt−1)+1−αtϵt=αtαt−1xt−2+两个相互独立的0均值的高斯分布相加αt−αtαt−1ϵt−1+1−αtϵt=αtαt−1xt−2+用一个新的高斯分布代替αt−αtαt−12+1−αt2ϵ=αtαt−1xt−2+1−αtαt−1ϵ=i=1∏tαix0+1−i=1∏tαiϵ=αtx0+1−αtϵ,αt=i=1∏tαi,ϵ∼N(0,I)∼N(αtx0,(1−αt)I)
我们发现只要设置了超参数α0:T的值,这个前向计算过程是可以直接解析(使用公式)计算的, 没有未知参数,不需要用一个模型学习这个过程。
逆向过程是从右到左的解码过程,从随机高斯噪声开始,逐步解码为一个有意义的数据。按照逆向过程对联合概率p(x0:T)进行分解
p(x0:T)=p(xT)t=T−1∏0p(xt∣xt+1)
我们可以知道p(xT)的概率密度,**是一个标准高斯分布,这是前向过程的目标。**但是pθ(xt∣xt+1)是难以计算的。
pθ(xt∣xt+1)=p(xt+1)p(xt+1∣xt)p(xt)=∫p(xt+1∣xt)p(xt)dxtp(xt+1∣xt)p(xt)
这种情况下要对所有可能的xt进行积分,显然是不可能做到的。所以我们可以用一个模型去拟合pθ(xt∣xt+1)的,从而生成一张真实图片。
**同前面的VAE的数学推导,**我们可以用极大似然估计来极大化真实图片概率p(x0)(边际分布)。
p(x0)=∫p(x0:T)dx1:T
显然无法直接通过这个式子求出p(x0),存在隐变量无法直接积分,下面来推导ELBO。
lnp(x0)=ln∫p(x0:T)dx1:T=ln∫q(x1:T∣x0)p(x0:T)q(x1:T∣x0)dx1:T=lnEq(x1:T∣x0)[q(x1:T∣x0)p(x0:T)]≥Eq(x1:T∣x0)[lnq(x1:T∣x0)p(x0:T)]=Eq(x1:T∣x0)[ln∏t=1Tq(xt∣xt−1)p(xT)∏t=1Tpθ(xt−1∣xt)]=Eq(x1:T∣x0)[lnq(xT∣xT−1)∏t=1T−1q(xt∣xt−1)p(xT)pθ(x0∣x1)∏t=2Tpθ(xt−1∣xt)]=Eq(x1:T∣x0)[lnq(xT∣xT−1)∏t=1T−1q(xt∣xt−1)p(xT)pθ(x0∣x1)∏t=1T−1pθ(xt∣xt+1)]=Eq(x1:T∣x0)[lnq(xT∣xT−1)p(xT)pθ(x0∣x1)]+Eq(x1:T∣x0)[lnt=1∏T−1q(xt∣xt−1)pθ(xt∣xt+1)]=Eq(x1:T∣x0)[lnpθ(x0∣x1)]+Eq(x1:T∣x0)[lnq(xT∣xT−1)p(xT)]+Eq(x1:T∣x0)[t=1∑T−1lnq(xt∣xt−1)pθ(xt∣xt+1)]=Eq(x1∣x0)[lnpθ(x0∣x1)]+Eq(xT−1,xT∣x0)[lnq(xT∣xT−1)p(xT)]+t=1∑T−1Eq(xt−1,xt,xt+1∣x0)[lnq(xt∣xt−1)pθ(xt∣xt+1)]=重建项Eq(x1∣x0)[lnpθ(x0∣x1)]−先验匹配项Eq(xT−1,xT∣x0)[lnq(xT∣xT−1)p(xT)]−一致项t=1∑T−1Eq(xt−1,xt,xt+1∣x0)[lnq(xt∣xt−1)pθ(xt∣xt+1)]
我们接着来说明倒数第三个等式如何推成倒数第二个等式:(本质是对无关变量进行边缘化)
核心公式:
q(xT−1∣x0)=∫q(x1∣x0)q(x2∣x1)…q(xT−1∣xT−2)dx1:T−2=∫q(x1∣x0)q(x2∣x1,x0)…q(xT−1∣xT−2,xT−3…,x0)dx1:T−2=∫q(x0)q(x0:T)dx1:T−2=∫q(x1:T∣x0)dx1:T−2=q(xT−1∣x0)
Eq(x1:T∣x0)[lnpθ(x0∣x1)]=∫lnpθ(x0∣x1)q(x1:T∣x0)dx1:T=∫lnpθ(x0∣x1)q(x1∣x0)dx11(积分归一性)∫2∏T−1q(xt∣xt−1)dx2:T=Eq(x1∣x0)[lnpθ(x0∣x1)]
Eq(x1:T∣x0)[lnq(xT∣xT−1)p(xT)]=∫lnq(xT∣xT−1)p(xT)q(x1:T∣x0)dx1:T=∫lnq(xT∣xT−1)p(xT)q(xT∣xT−1)dxT−1,T积分归一性:q(xT−1∣x0)∫t=1∏T−1q(xt∣xt−1)dx1:T−2=∫lnq(xT∣xT−1)p(xT)q(xT∣xT−1)q(xT−1∣x0)dxT−1,T=∫lnq(xT∣xT−1)p(xT)q(xT−1,xT∣x0)dxT−1,T=Eq(xT−1,xT∣x0)[lnq(xT∣xT−1)p(xT)]
Eq(x1:T∣x0)[t=1∑T−1lnq(xt∣xt−1)pθ(xt∣xt+1)]=t=1∑T−1∫lnq(xt∣xt−1)pθ(xt∣xt+1)q(x1:T∣x0)dx1:T=t=1∑T−1∫lnq(xt∣xt−1)pθ(xt∣xt+1)k=1∏Tq(xk−1∣xk)dx1:T=t=1∑T−1∫lnq(xt∣xt−1)pθ(xt∣xt+1)q(xt∣xt−1)q(xt+1∣xt)dxt−1,xt,xt+1∫1∏t
接着来看最后ELBO的三个式子:
- Eq(x1∣x0)[lnpθ(x0∣x1)]:重建项,和原始的VAE的第一项相同,从第一步的隐变量x1重建回原来的数据x0
- Eq(xT−1,xT∣x0)[lnq(xT∣xT−1)p(xT)]:先验匹配项,这一项没用学习参数,当T足够大的时候可以认为这一项是0
- ∑t=1T−1Eq(xt−1,xt,xt+1∣x0)[lnq(xt∣xt−1)pθ(xt∣xt+1)]:KL散度度量,一致项,这一项制约着在每一个时刻t,解码器预测的内容和编码器生成的内容要一致
- 初始扩散模型前向过程的线性高斯变换已经给出,前向过程进行到最后是一个标准高斯分布,但是也可以采取不同的线性高斯变换,只要加噪到最后是一个标准高斯分布即可,殊途同归
- 扩散模型前向过程的参数是人为定义的,没有需要学习的参数
- 反向生成的过程:扩散模型反向生成的每一步都是希望能够直接生成原始图像的,在后续数学推导可见得,有点囫囵吞枣的意味,这说明他的性能有上限,设计具有局限性,后面的DDPI改善了此问题
- 扩散模型相较VAE能够学习到更深层的特征,因为有T层的加噪和T层的还原,VAE只有一步重建
- 计算期望的时候由于无法直接积分,采用采样法(MCMC)进行均值计算
学习如何预测噪声,而不是直接生成图像
- 从真实图像数据分布q(x0)中采样一张干净图像x0
- 从均匀分布Uniform(1,...,T)中随机抽取一个时间步t
- 从N(0,I)采样出噪声ϵ
- 根据∇θ∥ϵ−ϵθ(αtx0+1−αtϵ,t)∥2作梯度下降
- αt与第几次去噪有关,次数多说明真正的图片x0占比大
- 让模型学会预测噪声,以便在反向采样时去噪
 image-20250511112847361
image-20250511112847361实际生成新图像
- 从正态分布中采样一个图像XT
- 从正态分布中采样一个噪声z
- 使用公式进行迭代xt−1=αt1(xt−1−αt1−αtϵθ(xt,t))+σtz
- xt−1为第t−1次的去噪结果
- αt,αt与第几次去噪有关
- ϵθ(xt,t)是一个噪声预测器
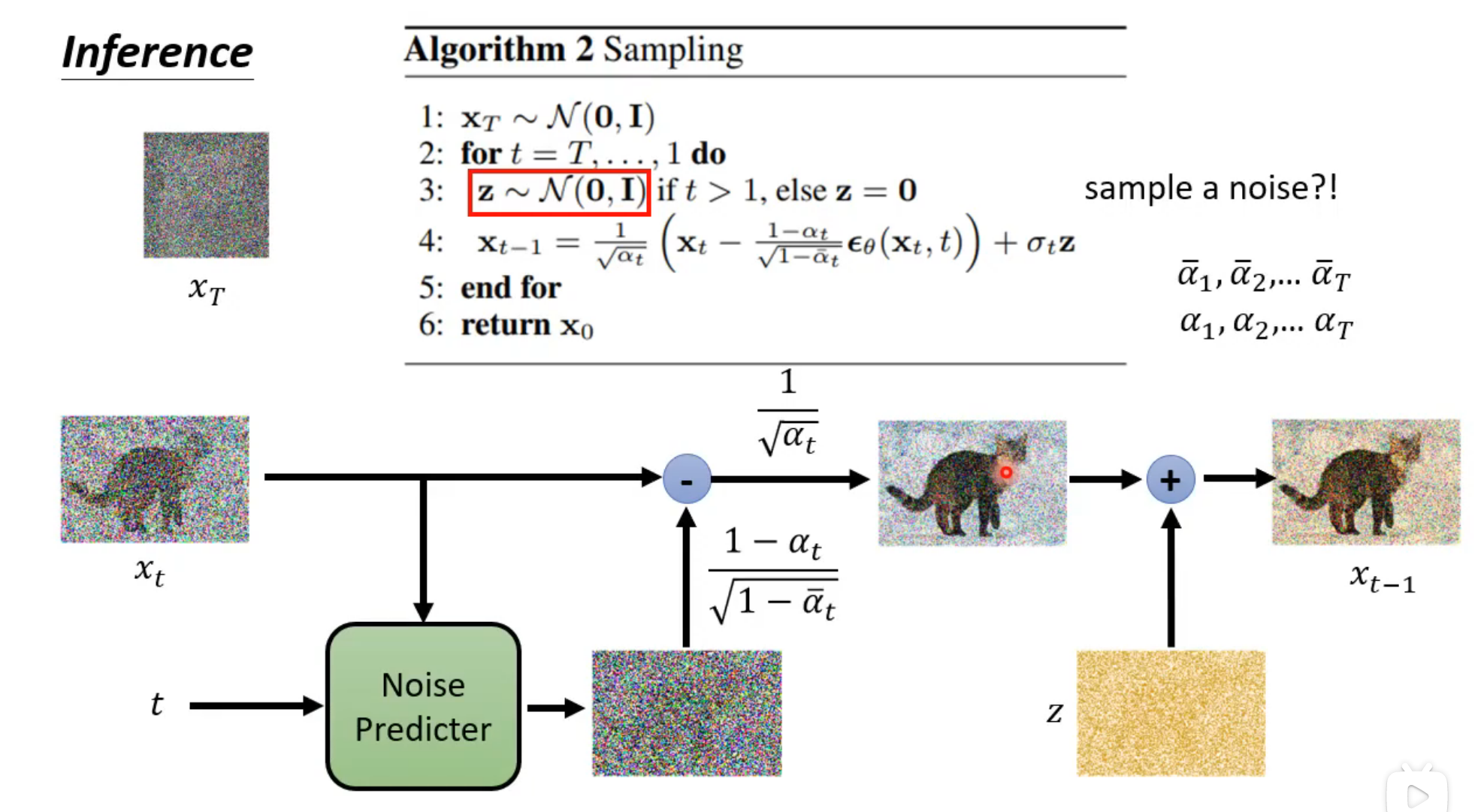 image-20250511111842681
image-20250511111842681