本页PDF
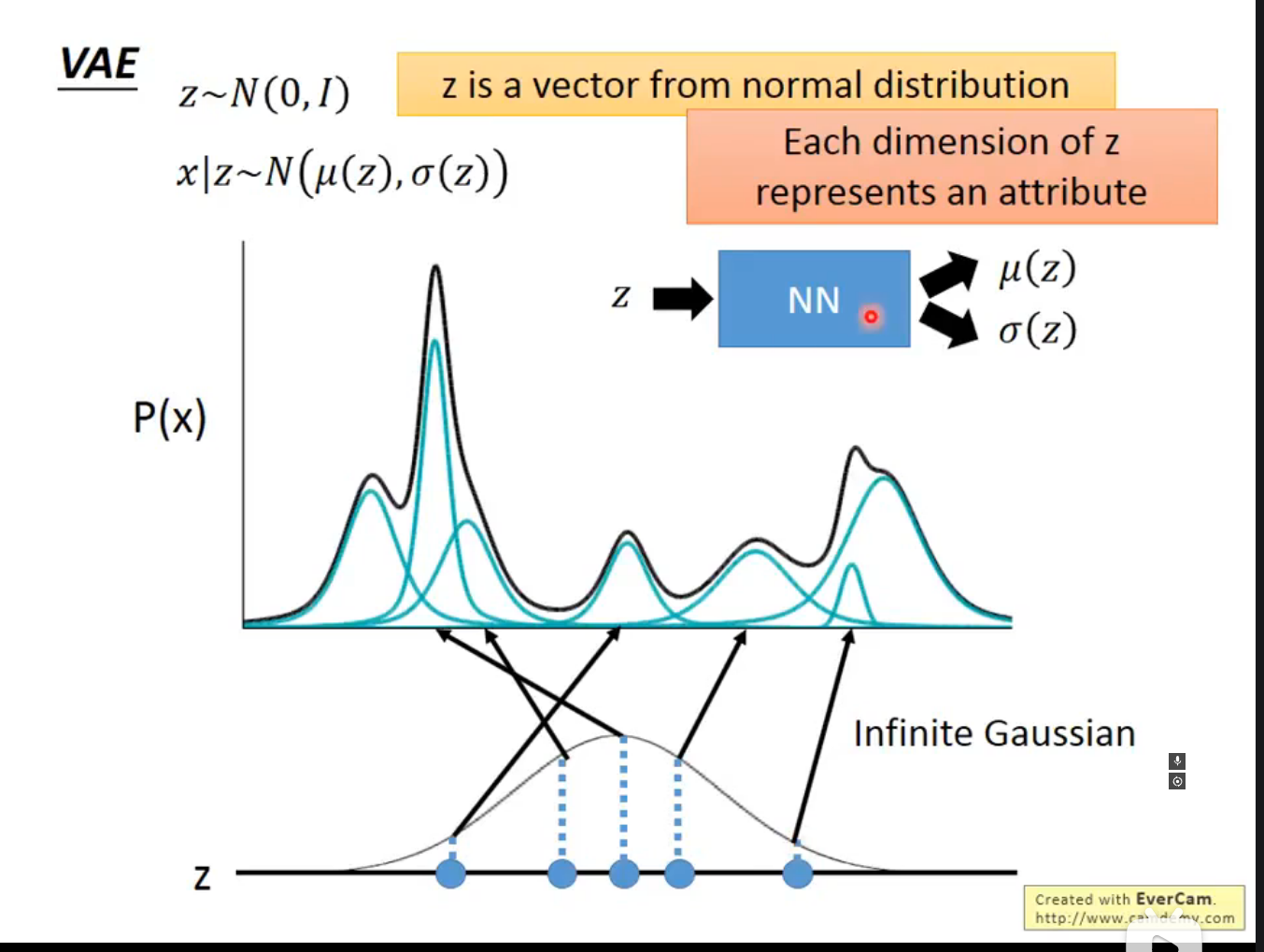
与 AE 结构相似,但是用了特殊技巧使得 VAE的decoder 对于一个 随机的向量 可以产生结果较好的图 自编码器将输入图像压缩为低维潜在向量,然后通过解码器重建图像 关键局限:形成的是严格的一对一映射关系 潜在空间不连续,缺乏良好的插值特性 无法生成新的、有意义的样本 VAE不是学习确定的潜在向量,而是学习概率分布 每个输入被映射到潜在空间中的分布(通常是高斯分布),由均值向量(μ \mu μ σ 2 \sigma^2 σ 2 核心思想 :通过学习分布而非单点表示,实现了潜在空间的连续性和平滑性通过学习分布而非固定点 ,VAE能够在潜在空间中的相邻点产生相似但不完全相同 的图像,使得整个潜在空间连续且有意义 ,从而可以从中随机采样生成新的图像。 P ( x ) P(x) P ( x )
z z z x x x z z z P ( x ) P(x) P ( x ) x x x
在这里假设 z z z z z z 无法穷举 的,因为特征 是一个抽象的东西 VAE的真正训练目标 是最大化数据的边缘似然 P(x)
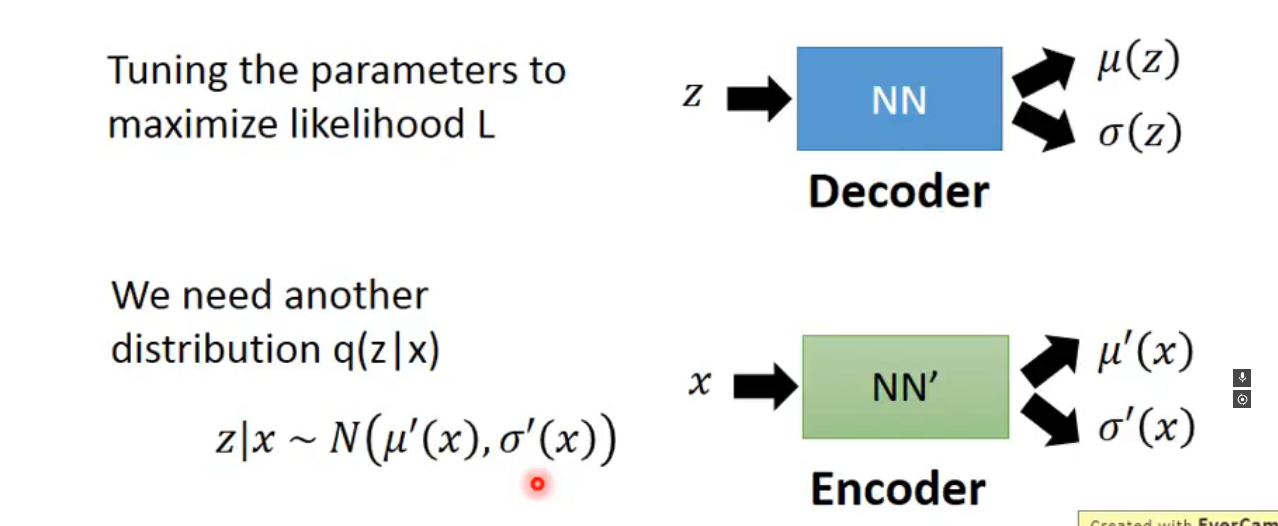
P ( x ) = ∫ P ( z ) P ( x ∣ z ) P(x) = \int P(z)P(x|z) P ( x ) = ∫ P ( z ) P ( x ∣ z ) z z z N ( 0 , I ) N(0,I) N ( 0 , I ) 解码器将 z z z x x x 最终的 P ( x ) P(x) P ( x ) image-20250430233601234 **Decoder:**将潜在变量 z z z ( N N ) (NN) ( NN ) P ( x ∣ z ) P(x|z) P ( x ∣ z ) μ ( z ) \mu(z) μ ( z ) σ ( z ) \sigma(z) σ ( z ) z z z x x x P ( x ∣ z ) P(x|z) P ( x ∣ z ) **Encoder:**将观测数据 x x x ( N N ′ ) (NN') ( N N ′ ) q ( z ∣ x ) q(z|x) q ( z ∣ x ) μ ′ ( x ) \mu'(x) μ ′ ( x ) σ ′ ( x ) \sigma'(x) σ ′ ( x ) P ( z ∣ x ) P(z|x) P ( z ∣ x ) image-20250501000147212 有疑问可以参考1. 变分自编码器(Variational Autoencoder) — 张振虎的博客 张振虎 文档
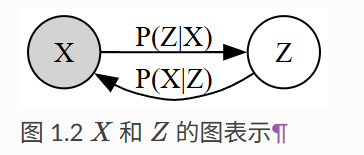
X为可观测变量(Observed variable),Z 为不可观测变量(Unobserved variable)
X为图片样本,Z表示潜在空间中的数据
从X到Z相当于给定X求Z的条件概率 P ( Z ∣ X ) P(Z|X) P ( Z ∣ X ) 从Z到X相当于给定Z求X的条件概率 P ( X ∣ Z ) P(X|Z) P ( X ∣ Z ) image-20250502115738249 完整的模型表示是二者的联合概率分布 P ( X , Z ) P(X,Z) P ( X , Z )
我们用 D \mathcal{D} D 如果X和Z都可以观测到 ,那么 D = { ( z ( 1 ) , x ( 1 ) ) , ⋯ , ( z ( N ) , x ( N ) ) } \mathcal{D} =\{(z^{(1)},x^{(1)}),\cdots,(z^{(N)},x^{(N)})\} D = {( z ( 1 ) , x ( 1 ) ) , ⋯ , ( z ( N ) , x ( N ) )}
L ( θ ; D ) = ∑ i = 1 N ln p θ ( z ( i ) , x ( i ) ) (1.1) \mathcal{L}(\theta;\mathcal{D}) = \sum_{i=1}^N \ln p_{\theta}(z^{(i)},x^{(i)}) \tag{1.1} L ( θ ; D ) = i = 1 ∑ N ln p θ ( z ( i ) , x ( i ) ) ( 1.1 )
但是我们并没有Z的观测样本 ,此时观测样本集合为 D = { x ( 1 ) , ⋯ , x ( N ) } \mathcal{D} =\{x^{(1)},\cdots,x^{(N)}\} D = { x ( 1 ) , ⋯ , x ( N ) }
L ( θ ; D ) = ∑ i = 1 N ln p θ ( x ( i ) ) = ∑ i = 1 N ln ∫ z p θ ( x ( i ) , z ) d z (1.2) \mathcal{L}(\theta;\mathcal{D}) = \sum_{i=1}^N \ln{p_{\theta}(x^{(i)})} = \sum_{i=1}^N \ln{\int_{z}{p_{\theta}(x^{(i)},z)dz}} \tag{1.2} L ( θ ; D ) = i = 1 ∑ N ln p θ ( x ( i ) ) = i = 1 ∑ N ln ∫ z p θ ( x ( i ) , z ) d z ( 1.2 )
积分难以计算,无法直接求解
补充 Jensen 不等式
对于凹函数 f ( x ) ,有如下关系 f ( E [ X ] ) ≥ E [ f ( X ) ] 而对于凸函数,不等号方向相反 \text{对于凹函数 } f(x) \text{,有如下关系} \\ f(\mathbb{E}[X]) \geq \mathbb{E}[f(X)] \\ \text{而对于凸函数,不等号方向相反} 对于凹函数 f ( x ) ,有如下关系 f ( E [ X ]) ≥ E [ f ( X )] 而对于凸函数,不等号方向相反
定义一个变量Z的概率密度函数 q ϕ ( z ∣ x ) q_{\phi}(z|x) q ϕ ( z ∣ x )
推导出公式(1.2)的下界函数
L ( θ ; x ) = ln p θ ( x ) = ln ∫ z p θ ( x , z ) = ln ∫ z q ϕ ( z ∣ x ) p θ ( x , z ) q ϕ ( z ∣ x ) 同时乘除 q ϕ ( z ∣ x ) ,等于没变化 = ln E q ϕ ( z ∣ x ) [ p θ ( x , z ) q ϕ ( z ∣ x ) ] ≥ E q ϕ ( z ∣ x ) ln [ p θ ( x , z ) q ϕ ( z ∣ x ) ] 根据Jensen不等式 = ∫ z q ϕ ( z ∣ x ) ln [ p θ ( x , z ) q ϕ ( z ∣ x ) ] = [ ∫ z q ϕ ( z ∣ x ) ln p θ ( x , z ) − ∫ z q ϕ ( z ∣ x ) ln q ϕ ( z ∣ x ) ] ≜ L ( q , θ ) \begin{aligned} \mathcal{L}(\theta;x) &= \ln p_{\theta}(x) \\ &=\ln \int_z{p_{\theta}(x,z)} \\ &=\ln \int_z{q_{\phi}(z|x)\frac{p_{\theta}(x,z)}{q_{\phi}(z|x)}} \quad \text{同时乘除}q_{\phi}(z|x)\text{,等于没变化}\\ &= \ln \mathbb{E}_{q_{\phi}(z|x)}[\frac{p_{\theta}(x,z)}{q_{\phi}(z|x)}] \\ &\geq \mathbb{E}_{q_{\phi}(z|x)} \ln{[\frac{p_{\theta}(x,z)}{q_{\phi}(z|x)}]} \quad \text{根据Jensen不等式} \\ &=\int_z{q_{\phi}(z|x)}\ln{[\frac{p_{\theta}(x,z)}{q_{\phi}(z|x)}]} \\ &=[\int_z{q_{\phi}(z|x)\ln{p_{\theta}(x,z)}} - \int_z{q_{\phi}(z|x)}\ln{q_{\phi}(z|x)}] \\ &\triangleq \mathcal{L}(q,\theta) \end{aligned} L ( θ ; x ) = ln p θ ( x ) = ln ∫ z p θ ( x , z ) = ln ∫ z q ϕ ( z ∣ x ) q ϕ ( z ∣ x ) p θ ( x , z ) 同时乘除 q ϕ ( z ∣ x ) ,等于没变化 = ln E q ϕ ( z ∣ x ) [ q ϕ ( z ∣ x ) p θ ( x , z ) ] ≥ E q ϕ ( z ∣ x ) ln [ q ϕ ( z ∣ x ) p θ ( x , z ) ] 根据 Jensen 不等式 = ∫ z q ϕ ( z ∣ x ) ln [ q ϕ ( z ∣ x ) p θ ( x , z ) ] = [ ∫ z q ϕ ( z ∣ x ) ln p θ ( x , z ) − ∫ z q ϕ ( z ∣ x ) ln q ϕ ( z ∣ x ) ] ≜ L ( q , θ )
找到下界函数 (ELBO) L ( q , θ ) \mathcal{L}(q,\theta) L ( q , θ )
L ( q , θ ) = [ ∫ z q ϕ ( z ∣ x ) ln p θ ( x , z ) − ∫ z q ϕ ( z ∣ x ) ln q ϕ ( z ∣ x ) ] = E z ∼ q ϕ [ ln p θ ( x , z ) ] − E z ∼ q ϕ [ ln q ϕ ( z ∣ x ) ] \begin{aligned} \mathcal{L}(q,\theta) &=[\int_z{q_{\phi}(z|x)\ln{p_{\theta}(x,z)}} - \int_z{q_{\phi}(z|x)}\ln{q_{\phi}(z|x)}] \\ &= \mathbb{E}_{z \sim q_{\phi}}[\ln{p_{\theta}(x,z)}] - \mathbb{E}_{z \sim q_{\phi}}[\ln{q_{\phi}(z|x)}] \end{aligned} L ( q , θ ) = [ ∫ z q ϕ ( z ∣ x ) ln p θ ( x , z ) − ∫ z q ϕ ( z ∣ x ) ln q ϕ ( z ∣ x ) ] = E z ∼ q ϕ [ ln p θ ( x , z ) ] − E z ∼ q ϕ [ ln q ϕ ( z ∣ x ) ]
而 p ( x , z ) = p ( z ) p ( x ∣ z ) = p ( x ) p ( z ∣ x ) p(x,z) = p(z)p(x|z) = p(x)p(z|x) p ( x , z ) = p ( z ) p ( x ∣ z ) = p ( x ) p ( z ∣ x ) 下界函数ELBO
使用 z z z p ( z ∣ x ) p(z|x) p ( z ∣ x )
L ( q , θ ) = E z ∼ q ϕ [ ln p θ ( x , z ) ] − E z ∼ q ϕ [ ln q ϕ ( z ∣ x ) ] = E z ∼ q ϕ [ ln p θ ( x ) + ln p θ ( z ∣ x ) ] − E z ∼ q ϕ [ ln q ϕ ( z ∣ x ) ] = E z ∼ q ϕ [ ln p θ ( x ) ] ⏟ 与z无关,期望符号可以直接去掉 + E z ∼ q ϕ [ ln p θ ( z ∣ x ) ] − E z ∼ q ϕ [ ln q ϕ ( z ∣ x ) ] = ln p θ ( x ) ⏟ 观察数据对数似然/证据 + E z ∼ q ϕ [ ln p θ ( z ∣ x ) ] − E z ∼ q ϕ [ ln q ϕ ( z ∣ x ) ] ⏟ KL散度 = ℓ ( θ ; x ) ⏟ 观察数据对数似然/证据 − K L ( q ϕ ( z ∣ x ) ∣ ∣ p θ ( z ∣ x ) ) ⏟ KL散度 \begin{aligned} \mathcal{L}(q,\theta) &= \mathbb{E}_{z \sim q_{\phi}}[\ln{p_{\theta}(x,z)}] - \mathbb{E}_{z \sim q_{\phi}}[\ln{q_{\phi}(z|x)}] \\ &= \mathbb{E}_{z \sim q_{\phi}}[\ln{p_{\theta}(x)}+\ln{p_{\theta}(z|x)}] - \mathbb{E}_{z \sim q_{\phi}}[\ln{q_{\phi}(z|x)}] \\ &= \underbrace{\mathbb{E}_{z \sim q_{\phi}}[\ln{p_{\theta}(x)}]}_{\text{与z无关,期望符号可以直接去掉}}+\mathbb{E}_{z \sim q_{\phi}}[{\ln{p_{\theta}(z|x)}}] - \mathbb{E}_{z \sim q_{\phi}}[\ln{q_{\phi}(z|x)}] \\ &= \underbrace{\ln{p_{\theta}(x)}}_{\text{观察数据对数似然/证据}}+\underbrace{\mathbb{E}_{z \sim q_{\phi}}[{\ln{p_{\theta}(z|x)}}] - \mathbb{E}_{z \sim q_{\phi}}[\ln{q_{\phi}(z|x)}]}_{\text{KL散度}} \\ &= \underbrace{\ell(\theta;x)}_{\text{观察数据对数似然/证据}}-\underbrace{KL(q_{\phi}(z|x)||p_{\theta}(z|x))}_{\text{KL散度}} \end{aligned} L ( q , θ ) = E z ∼ q ϕ [ ln p θ ( x , z ) ] − E z ∼ q ϕ [ ln q ϕ ( z ∣ x ) ] = E z ∼ q ϕ [ ln p θ ( x ) + ln p θ ( z ∣ x ) ] − E z ∼ q ϕ [ ln q ϕ ( z ∣ x ) ] = 与 z 无关,期望符号可以直接去掉 E z ∼ q ϕ [ ln p θ ( x ) ] + E z ∼ q ϕ [ ln p θ ( z ∣ x ) ] − E z ∼ q ϕ [ ln q ϕ ( z ∣ x ) ] = 观察数据对数似然 / 证据 ln p θ ( x ) + KL 散度 E z ∼ q ϕ [ ln p θ ( z ∣ x ) ] − E z ∼ q ϕ [ ln q ϕ ( z ∣ x ) ] = 观察数据对数似然 / 证据 ℓ ( θ ; x ) − KL 散度 K L ( q ϕ ( z ∣ x ) ∣∣ p θ ( z ∣ x ))
整理后可得到
ℓ ( θ ; x ) ⏟ 观察数据对数似然/证据 = L ( q , θ ) ⏟ 下界函数ELBO + K L ( q ϕ ( z ∣ x ) ∣ ∣ p θ ( z ∣ x ) ) ⏟ KL散度 \underbrace{\ell(\theta;x)}_{\text{观察数据对数似然/证据}} = \underbrace{\mathcal{L}(q,\theta)}_{\text{下界函数ELBO}} + \underbrace{KL(q_{\phi}(z|x)||p_{\theta}(z|x))}_{\text{KL散度}} 观察数据对数似然 / 证据 ℓ ( θ ; x ) = 下界函数 ELBO L ( q , θ ) + KL 散度 K L ( q ϕ ( z ∣ x ) ∣∣ p θ ( z ∣ x ))
L ( q , θ ) = E z ∼ q ϕ [ ln p θ ( x , z ) ] − E z ∼ q ϕ [ ln q ϕ ( z ) ] = E z ∼ q ϕ [ ln p ( z ) + ln p θ ( x ∣ z ) ] − E z ∼ q ϕ [ ln q ϕ ( z ) ] = E z ∼ q ϕ [ ln p ( z ) ] + E z ∼ q ϕ [ ln p θ ( x ∣ z ) ] − E z ∼ q ϕ [ ln q ϕ ( z ) ] = E z ∼ q ϕ [ ln p θ ( x ∣ z ) ] + E z ∼ q ϕ [ ln p ( z ) ] − E z ∼ q ϕ [ ln q ϕ ( z ) ] ⏟ KL散度 = E z ∼ q ϕ [ ln p θ ( x ∣ z ) ] − K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ) ) ⏟ q ϕ ( z ) 和先验 p ( z ) 的KL散度 \begin{aligned} \mathcal{L}(q,\theta) &= \mathbb{E}_{z \sim q_{\phi}}[\ln{p_{\theta}(x,z)}] - \mathbb{E}_{z \sim q_{\phi}}[\ln{q_{\phi}(z)}] \\ &= \mathbb{E}_{z \sim q_{\phi}}[\ln{p(z)}+\ln{p_{\theta}(x|z)}] - \mathbb{E}_{z \sim q_{\phi}}[\ln{q_{\phi}(z)}] \\ &= \mathbb{E}_{z \sim q_{\phi}}[\ln{p(z)}]+\mathbb{E}_{z \sim q_{\phi}}[{\ln{p_{\theta}(x|z)}}] - \mathbb{E}_{z \sim q_{\phi}}[\ln{q_{\phi}(z)}] \\ &= \mathbb{E}_{z \sim q_{\phi}}[{\ln{p_{\theta}(x|z)}}]+\underbrace{\mathbb{E}_{z \sim q_{\phi}}[{\ln{p(z)}}] - \mathbb{E}_{z \sim q_{\phi}}[\ln{q_{\phi}(z)}]}_{\text{KL散度}} \\ &= \mathbb{E}_{z \sim q_{\phi}}[{\ln{p_{\theta}(x|z)}}] - \underbrace{KL(q_{\phi}(z|x)||p(z))}_{q_{\phi}(z)\text{和先验}p(z)\text{的KL散度}} \end{aligned} L ( q , θ ) = E z ∼ q ϕ [ ln p θ ( x , z ) ] − E z ∼ q ϕ [ ln q ϕ ( z ) ] = E z ∼ q ϕ [ ln p ( z ) + ln p θ ( x ∣ z ) ] − E z ∼ q ϕ [ ln q ϕ ( z ) ] = E z ∼ q ϕ [ ln p ( z ) ] + E z ∼ q ϕ [ ln p θ ( x ∣ z ) ] − E z ∼ q ϕ [ ln q ϕ ( z ) ] = E z ∼ q ϕ [ ln p θ ( x ∣ z ) ] + KL 散度 E z ∼ q ϕ [ ln p ( z ) ] − E z ∼ q ϕ [ ln q ϕ ( z ) ] = E z ∼ q ϕ [ ln p θ ( x ∣ z ) ] − q ϕ ( z ) 和先验 p ( z ) 的 KL 散度 K L ( q ϕ ( z ∣ x ) ∣∣ p ( z ))
根据前文的结论,当 q ϕ ( z ) q_{\phi}(z) q ϕ ( z ) z z z p θ ( z ∣ x ) p_{\theta}(z|x) p θ ( z ∣ x ) L ( q , θ ) \mathcal{L}(q,\theta) L ( q , θ ) ℓ ( θ ; x ) \ell(\theta;x) ℓ ( θ ; x ) q ϕ ( z ) = p θ ( z ∣ x ) q_{\phi}(z) = p_{\theta}(z|x) q ϕ ( z ) = p θ ( z ∣ x ) q ϕ ( z ) = q ϕ ( z ∣ x ) q_{\phi}(z)=q_{\phi}(z|x) q ϕ ( z ) = q ϕ ( z ∣ x )
L ( q , θ ) = E z ∼ q ϕ ( z ∣ x ) [ ln p θ ( x ∣ z ) ] ⏟ 重建项(reconstruction term) − K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ) ) ⏟ 先验匹配项(prior matching term) = ℓ ( θ ; x ) \begin{aligned} \mathcal{L}(q,\theta) &= \underbrace{\mathbb{E}_{z \sim q_{\phi}(z|x)}[{\ln{p_{\theta}(x|z)}}]}_{\text{重建项(reconstruction term)}}- \underbrace{KL(q_{\phi}(z|x)||p(z))}_{\text{先验匹配项(prior matching term)}} \\ &= \ell(\theta;x) \end{aligned} L ( q , θ ) = 重建项 (reconstruction term) E z ∼ q ϕ ( z ∣ x ) [ ln p θ ( x ∣ z ) ] − 先验匹配项 (prior matching term) K L ( q ϕ ( z ∣ x ) ∣∣ p ( z )) = ℓ ( θ ; x )
分布 含义 是否学习 网络对应 p ( z ) p(z) p ( z ) 潜变量的先验分布 否,通常固定为N(0,I) 无 $q_{\phi}(z x)$ 近似后验分布 是,学习参数ϕ \phi ϕ $p_{\theta}(x z)$ 条件生成分布 是,学习参数θ \theta θ $p_{\theta}(z x)$ 真实后验分布 理论上是,但难以直接计算 p θ ( x ) p_{\theta}(x) p θ ( x ) 数据的边缘分布 理论上是,但难以直接优化 整个VAE
p ( z ) p(z) p ( z ) z z z 假设分布 ,通常是正态分布p ( z ∣ x ) p(z|x) p ( z ∣ x ) z z z 真实后验 实际情况中真实后验难以计算 (因为要对 z z z z z z z z z 我们希望编码器的输出可以接近我们假设的 z z z ELBO 最大,从而使对数似然最大 后验分布 q ϕ ( z ∣ x ) q_{\phi}(z|x) q ϕ ( z ∣ x ) 高斯分布 ,但我们不知道其均值和方差。这里我们分别用 μ z \mu_z μ z Σ z \Sigma_z Σ z q ϕ ( z ∣ x ) = N ( μ z , Σ z ) q_{\phi}(z|x) = \mathcal{N}(\mu_z,\Sigma_z) q ϕ ( z ∣ x ) = N ( μ z , Σ z ) Z Z Z Σ z \Sigma_z Σ z 未知参数 。
在 VAE 中,Z 是一个 随机变量 ,不能从 X X X Z Z Z X X X Z Z Z Z Z Z μ z \mu_z μ z Σ z \Sigma_z Σ z x x x
μ z = μ ϕ ( x ) = encoder ϕ ( x ) Σ z = Σ ϕ ( x ) = encoder ϕ ( x ) \begin{aligned} \mu_z &= \mu_{\phi}(x) = \text{encoder}_{\phi}(x) \\ \Sigma_z &= \Sigma_{\phi}(x) = \text{encoder}_{\phi}(x) \end{aligned} μ z Σ z = μ ϕ ( x ) = encoder ϕ ( x ) = Σ ϕ ( x ) = encoder ϕ ( x )
K L ( q ϕ ( z ) ∣ ∣ p ( z ) ) = K L ( N ( μ z , Σ z ) ∣ ∣ N ( 0 , I ) ) = 1 2 ( tr ( Σ z ) + μ z T μ z − k − log det ( Σ z ) ) \begin{aligned} KL(q_{\phi}(z)||p(z)) &= KL(\mathcal{N}(\mu_z,\Sigma_z)||\mathcal{N}(0,I)) \\ &= \frac{1}{2}(\text{tr}(\Sigma_z)+\mu_z^T\mu_z-k-\log{\det(\Sigma_z)}) \end{aligned} K L ( q ϕ ( z ) ∣∣ p ( z )) = K L ( N ( μ z , Σ z ) ∣∣ N ( 0 , I )) = 2 1 ( tr ( Σ z ) + μ z T μ z − k − log det ( Σ z ) )
上述是模型训练过程目标函数的一项,k k k 正则项 ,使得后验 q ϕ ( z ∣ x ) q_{\phi}(z|x) q ϕ ( z ∣ x ) z z z
E z ∼ q ϕ ( z ∣ x ) [ ln p θ ( x ∣ z ) ] ⏟ 重建项(reconstruction term) \underbrace{\mathbb{E}_{z \sim q_{\phi}(z|x)}[{\ln{p_{\theta}(x|z)}}]}_{\text{重建项(reconstruction term)}} 重建项 (reconstruction term) E z ∼ q ϕ ( z ∣ x ) [ ln p θ ( x ∣ z ) ] Z Z Z X X X z z z x x x z z z X X X μ x \mu_x μ x z z z X X X Σ x \Sigma_x Σ x 假设 X X X I I I
μ x = μ θ ( z ) = decoder θ ( z ) \mu_x = \mu_{\theta}(z) = \text{decoder}_{\theta}(z) μ x = μ θ ( z ) = decoder θ ( z )
因为编码器的输出是 Z Z Z 马尔科夫链蒙特卡洛法 ,即采样法近似实现 。其实就是从后验概率分布 q ϕ ( z ∣ x ) q_{\phi}(z|x) q ϕ ( z ∣ x ) z z z
E z ∼ q ϕ ( z ∣ x ) [ ln p θ ( x ∣ z ) ] ≈ 1 L ∑ l = 1 L [ ln p θ ( x ∣ z ( l ) ) ] \mathbb{E}_{z \sim q_{\phi}(z|x)}[{\ln{p_{\theta}(x|z)}}] \approx \frac{1}{L}\sum_{l=1}^L[\ln{p_{\theta}(x|z^{(l)})}] E z ∼ q ϕ ( z ∣ x ) [ ln p θ ( x ∣ z ) ] ≈ L 1 l = 1 ∑ L [ ln p θ ( x ∣ z ( l ) ) ]
采样次数 L L L L = 1 L=1 L = 1 随机采样 ,即 z z z 不可导 的,这导致梯度不能从解码器传递到编码器。VAE 的作者, 在这里采用重参数化 (reparameterization trick)的技巧来解决这个问题。
重参数化的思想其实很简单,就是稍微调整了一下采样的方法
我们要从后验分布 q ϕ ( x ∣ z ) q_{\phi}(x|z) q ϕ ( x ∣ z ) z z z N ( μ z , Σ z ) \mathcal{N}(\mu_z,\Sigma_z) N ( μ z , Σ z ) 任意均值和方差的高斯分布都可以从一个标准正态分布 N ( 0 , I ) \mathcal{N}(0,I) N ( 0 , I ) ,我们用符号 ϵ \epsilon ϵ ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0,I) ϵ ∼ N ( 0 , I ) N ( μ z , Σ z ) \mathcal{N}(\mu_z,\Sigma_z) N ( μ z , Σ z )
z = μ z + Σ z ⊙ ϵ = μ θ ( x ) + Σ ϕ ( x ) ⊙ ϵ , ϵ ∼ N ( 0 , I ) \begin{aligned} z &= \mu_z + \sqrt{\Sigma_z} \odot \epsilon \\ &=\mu_{\theta}(x)+\sqrt{\Sigma_{\phi}(x)} \odot \epsilon,\epsilon \sim \mathcal{N}(0,I) \end{aligned} z = μ z + Σ z ⊙ ϵ = μ θ ( x ) + Σ ϕ ( x ) ⊙ ϵ , ϵ ∼ N ( 0 , I )
也就是说,可以先从标准正态分布 N ( 0 , I ) \mathcal{N}(0,I) N ( 0 , I ) z z z ⊙ \odot ⊙ μ ϕ ( x ) \mu_{\phi}(x) μ ϕ ( x ) Σ ϕ ( x ) \sqrt{\Sigma_{\phi}(x)} Σ ϕ ( x ) ϵ \epsilon ϵ
回顾一下多维正态分布的表达式
p ( x ) = 1 ( 2 π ) n / 2 ∣ Σ ∣ 1 / 2 exp { − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) } p(x) = \frac{1}{(2\pi)^{n/2}|\Sigma|^{1/2}}\exp\{-\frac{1}{2}(x-\mu)^T\Sigma ^{-1}(x-\mu)\} p ( x ) = ( 2 π ) n /2 ∣Σ ∣ 1/2 1 exp { − 2 1 ( x − μ ) T Σ − 1 ( x − μ )}
在前面我们假设 p θ ( x ∣ z ) p_{\theta}(x|z) p θ ( x ∣ z ) 一个单位方差的高斯分布 ,根据高斯分布的概率密度函数,p θ ( x ∣ z ) p_{\theta}(x|z) p θ ( x ∣ z )
p ( x ) = 1 ( 2 π ) n / 2 ∣ Σ ∣ 1 / 2 exp { − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) } ∝ exp { − 1 2 ( x − μ x ) T ( x − μ x ) } = exp { − 1 2 ( x − μ θ ( z ) ) T ( x − μ θ ( z ) ) } = exp { − 1 2 ( x − decoder ( z ) ) T ( x − x − decoder ( z ) ) } \begin{aligned} p(x) &= \frac{1}{(2\pi)^{n/2}|\Sigma|^{1/2}}\exp\{-\frac{1}{2}(x-\mu)^T\Sigma ^{-1}(x-\mu)\} \\ & \propto \exp\{-\frac{1}{2}(x-\mu_x)^T(x-\mu_x)\} \\ &= \exp\{-\frac{1}{2}(x-\mu_{\theta}(z))^T(x-\mu_{\theta}(z))\} \\ &= \exp\{-\frac{1}{2}(x-\text{decoder}(z))^T(x-x-\text{decoder}(z))\} \\ \end{aligned} p ( x ) = ( 2 π ) n /2 ∣Σ ∣ 1/2 1 exp { − 2 1 ( x − μ ) T Σ − 1 ( x − μ )} ∝ exp { − 2 1 ( x − μ x ) T ( x − μ x )} = exp { − 2 1 ( x − μ θ ( z ) ) T ( x − μ θ ( z ))} = exp { − 2 1 ( x − decoder ( z ) ) T ( x − x − decoder ( z ))}
最后下界函数 E L B O ELBO E L BO
L ( q , θ ) = E z ∼ q ϕ [ ln p θ ( x ∣ z ) ] ⏟ 对应解码过程 − K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ) ) ⏟ 对应编码过程 = 1 L ∑ l = 1 L [ ln p θ ( x ∣ z ( l ) ) ] − K L ( N ( μ z , Σ z ) ∣ ∣ N ( 0 , I ) ) ∝ 1 L ∑ l = 1 L [ − 1 2 ( x − μ x ) T ( x − μ x ) ] − [ 1 2 ( tr ( Σ z ) + μ z T μ z − k − log det ( Σ z ) ) ] ∝ − 1 L ∑ l = 1 L [ ( x − μ x ) T ( x − μ x ) ] − [ ( tr ( Σ z ) + μ z T μ z − k − log det ( Σ z ) ) ] \begin{aligned} \mathcal{L}(q,\theta) &= \underbrace{\mathbb{E}_{z \sim q_{\phi}}[{\ln{p_{\theta}(x|z)}}]}_{\text{对应解码过程}} - \underbrace{KL(q_{\phi}(z|x)||p(z))}_{\text{对应编码过程}} \\ &= \frac{1}{L}\sum_{l=1}^L[\ln{p_{\theta}(x|z^{(l)})}] - KL(\mathcal{N}(\mu_z,\Sigma_z)||\mathcal{N}(0,I)) \\ &\propto \frac{1}{L}\sum_{l=1}^L[-\frac{1}{2}(x-\mu_x)^T(x-\mu_x)] - [\frac{1}{2}(\text{tr}(\Sigma_z)+\mu_z^T\mu_z-k-\log{\det(\Sigma_z)})]\\ & \propto -\frac{1}{L}\sum_{l=1}^L[(x-\mu_x)^T(x-\mu_x)] - [(\text{tr}(\Sigma_z)+\mu_z^T\mu_z-k-\log{\det(\Sigma_z)})]\\ \end{aligned} L ( q , θ ) = 对应解码过程 E z ∼ q ϕ [ ln p θ ( x ∣ z ) ] − 对应编码过程 K L ( q ϕ ( z ∣ x ) ∣∣ p ( z )) = L 1 l = 1 ∑ L [ ln p θ ( x ∣ z ( l ) ) ] − K L ( N ( μ z , Σ z ) ∣∣ N ( 0 , I )) ∝ L 1 l = 1 ∑ L [ − 2 1 ( x − μ x ) T ( x − μ x )] − [ 2 1 ( tr ( Σ z ) + μ z T μ z − k − log det ( Σ z ) )] ∝ − L 1 l = 1 ∑ L [( x − μ x ) T ( x − μ x )] − [( tr ( Σ z ) + μ z T μ z − k − log det ( Σ z ) )]
其中:
μ x = μ θ ( z ( l ) ) = decoder ( z ( l ) ) z ( l ) = μ z + Σ z ⊙ ϵ , ϵ ∼ N ( 0 , I ) μ z = μ ϕ ( x ) = encoder ( x ) μ z Σ z = Σ ϕ ( x ) = encoder ( x ) Σ z \begin{aligned} \mu_x &= \mu_{\theta}(z^{(l)}) = \text{decoder}(z^{(l)}) \\ z^{(l)} &= \mu_z + \sqrt{\Sigma_z} \odot \epsilon, \epsilon \sim \mathcal{N}(0,I)\\ \mu_z &= \mu_{\phi}(x) = \text{encoder}(x)_{\mu_z}\\ \Sigma_z &= \Sigma_{\phi}(x) = \text{encoder}(x)_{\Sigma_z} \end{aligned} μ x z ( l ) μ z Σ z = μ θ ( z ( l ) ) = decoder ( z ( l ) ) = μ z + Σ z ⊙ ϵ , ϵ ∼ N ( 0 , I ) = μ ϕ ( x ) = encoder ( x ) μ z = Σ ϕ ( x ) = encoder ( x ) Σ z
由于我们是通过极大化 L ( q , θ ) \mathcal{L}(q,\theta) L ( q , θ )
1 L ∑ l = 1 L [ ( x − μ x ) T ( x − μ x ) ⏟ 均方误差 ] \frac{1}{L}\sum_{l=1}^L[\underbrace{(x-\mu_x)^T(x-\mu_x)}_{\text{均方误差}}] L 1 l = 1 ∑ L [ 均方误差 ( x − μ x ) T ( x − μ x ) ]
和
( tr ( Σ z ) + μ z T μ z − k − log det ( Σ z ) ) (\text{tr}(\Sigma_z)+\mu_z^T\mu_z-k-\log{\det(\Sigma_z)}) ( tr ( Σ z ) + μ z T μ z − k − log det ( Σ z ) )
可以见得,第一项是均方误差,第二项是正则项。
重建项是为了能够通过 z z z x x x 先验匹配项是希望编码器生成的 z z z 使用的时候在给定的分布里抽样即可,这样解码器就能正确还原 编码器接收 x x x x x x 由于每张图像具有不同的特征,所以编码器要为每张图像输出属于他自己的高斯分布 L ( q , θ ) = E z ∼ q ϕ ( z ∣ x ) [ ln p θ ( x ∣ z ) ] ⏟ 重建项(reconstruction term) − K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ) ) ⏟ 先验匹配项(prior matching term) \mathcal{L}(q,\theta) = \underbrace{\mathbb{E}_{z \sim q_{\phi}(z|x)}[{\ln{p_{\theta}(x|z)}}]}_{\text{重建项(reconstruction term)}}- \underbrace{KL(q_{\phi}(z|x)||p(z))}_{\text{先验匹配项(prior matching term)}} L ( q , θ ) = 重建项 (reconstruction term) E z ∼ q ϕ ( z ∣ x ) [ ln p θ ( x ∣ z ) ] − 先验匹配项 (prior matching term) K L ( q ϕ ( z ∣ x ) ∣∣ p ( z ))
输入图像 x x x 编码器输出该图像对应的分布 μ , σ \mu,\sigma μ , σ 从分布中采样出 z z z 解码器用 z z z x ^ \hat{x} x ^ 对比 x x x x ^ \hat{x} x ^ 同时计算这个分布与 N ( 0 , 1 ) \mathcal{N}(0,1) N ( 0 , 1 ) 两部分误差加在一起做反向传播更新参数 基本概念:
自编码器是一种特殊的神经网络,主要目的是学习如何压缩和重建数据 。想象一下,你要把一张照片通过一个狭窄的管道传输,然后在另一端重新组装成 原来的样子。自编码器就是学习如何进行这种压缩和重建 的过程
核心特点:
试图将输入数据编码成一个低维表示(称为潜在空间或编码),然后再从这个低维表示重建原始输入数据
主要组成部分
自编码器主要由三个部分组成:
编码器**(Encoder)**: 将输入数据转换为较低维度的表示(称为"潜在表示"或"编码") 相当于压缩过程 通常由几层神经网络组成,逐渐减少神经元数量 潜在空间**(Latent Space)**: 编码后的数据存在的压缩表示空间 通常维度比原始数据小得多 包含了数据的主要特征信息 解码器**(Decoder)**: 将潜在表示转换回原始数据维度 相当于解压缩过程 结构通常是编码器的镜像,神经元数量逐渐增加 工作流程
输入数据(如图像)进入编码器 编码器将数据压缩到潜在空间(例如,从784维压缩到32维) 解码器尝试从潜在空间重建原始输入 比较重建结果与原始输入的差异(称为"重建误差") 通过反向传播调整编码器和解码器的参数,使重建误差最小化 自编码器的用途包括: