本页PDF
是Sequence to Sequence Model的一种
编码器解码器架构作用:让编码器全面理解输入序列的语义,并将其压缩为高阶表示(Context),解码器则基于此上下文信息,逐步生成目标序列
- Word Embedding(词向量嵌入)
- 把输入的每个词(一个ID)转换成一个向量,比如 512维。
- 使用可学习的
nn.Embedding 层实现。
- Positional Encoding(位置编码)
- 因为 Transformer 不像 RNN 有顺序结构,所以必须显式加入位置信息。
- 分两种方式:
- 原始论文用的是固定的正余弦函数
- 现在大多数用的是可学习的位置向量
一个 Encoder 包括多个重复的子层,即block块(通常是 6 层):
每层(个block)包含两个子模块:
- 多头注意力机制(Multi-Head Self Attention)
- 输入之间相互看 → 比如“我 爱 学习”,每个词都看整个句子
- 前馈神经网络(Feed Forward Network)
- 每个词单独处理,升维、激活、降维,类似 MLP
- 小型的全连接网络
每个子模块后都有:
作用:产生输出
- 会把上一个时间节点的输出当作当前时间节点的输入
- 是Auto-regressive(自回归)类型
基本构成
每一层 Decoder 包含 3 个子层 + 残差连接 + LayerNorm:
- 已生成的词作为带掩码自注意力的输入,要进行位置编码和词向量生成,且解码器的输入是随着解码器的输出不断变化的
- 经过编码器处理过的输入和带掩码自注意力的输出作为多头注意力的输入
Masked Multi-Head Self-Attention(带掩码的自注意力)
- 作用:让每个位置的词只能“看到自己和前面的词”
- 用法:防止 Decoder 在训练时“看到未来词” , 屏蔽未来信息
Encoder-Decoder Attention(跨模块注意力)
作用:让 Decoder 能看到 Encoder 编码过的输入序列
Query 来自 Decoder,Key 和 Value 来自 Encoder 的输出。
让 Decoder 能“参考”输入句子的语义信息,这样就可以用注意力机制让 Decoder“参考”输入句子,在生成翻译/回答/续写时更合理
Feed Forward Network(前馈神经网络)
- 结构:两个全连接层 + 激活函数**(ReLU/GeLU)**、
残差连接 + LayerNorm
每个子层后都加:
- 残差连接:
output = input + Sublayer(input) - LayerNorm:保持训练稳定、收敛更快
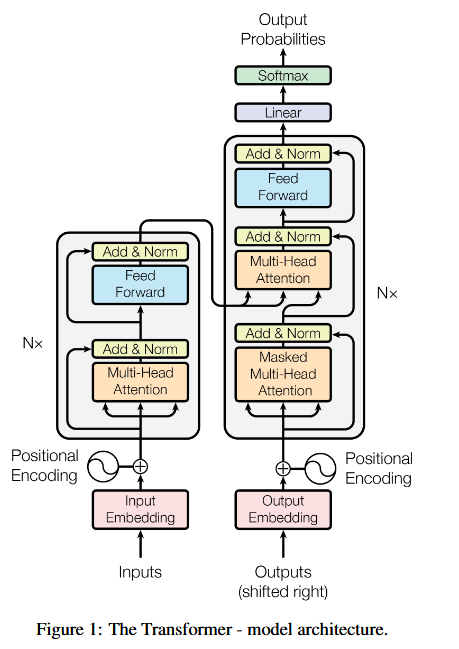 image-20250702225431058
image-20250702225431058Encoder:
Decoder:
Teacher Forcing:
- 在训练阶段,模型每一步的输入直接使用真实目标序列中的token(即“正确答案”),而不是模型自己生成的token
- 训练时,Decoder 不用自己的输出作为下一步输入
- 而是用真实的上一个词 , 快速学习,避免误差累积
Attention细节
- Decoder 内部的 Self-Attention: Mask 住后面的词,防止模型看到答案(实现自回归)
- Encoder-Decoder Attention: Decoder 的每一层都会“参考” Encoder 输出的语义向量,来帮助自己理解输入句子的含义
损失函数
- 每个位置的输出 → softmax → 得到一个词的概率分布
- 与真实词的 one-hot 编码做对比 → 使用 Cross Entropy Loss
优化目标
使所有预测位置的交叉熵损失最小化
即:模型学会尽可能接近地预测出目标句子中的每一个词。
训练时,Decoder 是可以看到“前面的正确答案”的,但不能看到“当前或未来的词”。这个技巧叫做 Teacher Forcing(教师强制)。
训练 Decoder 的时候:
- 模型生成第一个词的时候,输入
<BOS>(开始符) - 第二个词用 真实的第一个词(比如“我”)作为输入
- 第三个词用真实的“我 爱”
- …直到句尾
而 不是 用模型上一步自己预测的词作为下一步的输入。
这种做法就叫 Teacher Forcing。
基本原理
它将层的输入直接加到该层的输出上,形成"捷径"或"跳跃连接"。如果一个层的输入是x,输出是F(x),则残差连接后的最终输出是x + F(x)
缓解梯度消失
- 如果一个层的输出是 y=F(x)+x(残差连接)
- 那么反向传播时,梯度 ∂L/∂x 可以分解为两部分:
∂y∂L⋅∂x∂y=∂y∂L⋅(∂x∂F(x)+1)
- 即使 ∂x∂F(x) 很小,加上1后仍能保证有效的梯度传递
它是做标准化的,避免不同样本间分布不稳定。
- 与 BatchNorm 不同,它对的是一个样本内部的所有特征归一化,而不是整批样本。
- 在 NLP 序列建模中比 BatchNorm 更合适(因为样本长度不固定、batch 大小可能很小)
- Layer Normalization是对同一个feature不同的dimension进行归一化,Batch Normalization是对不同的feature的同一个dimension进行归一化
给定四个词,下面展示self-attention的计算过程
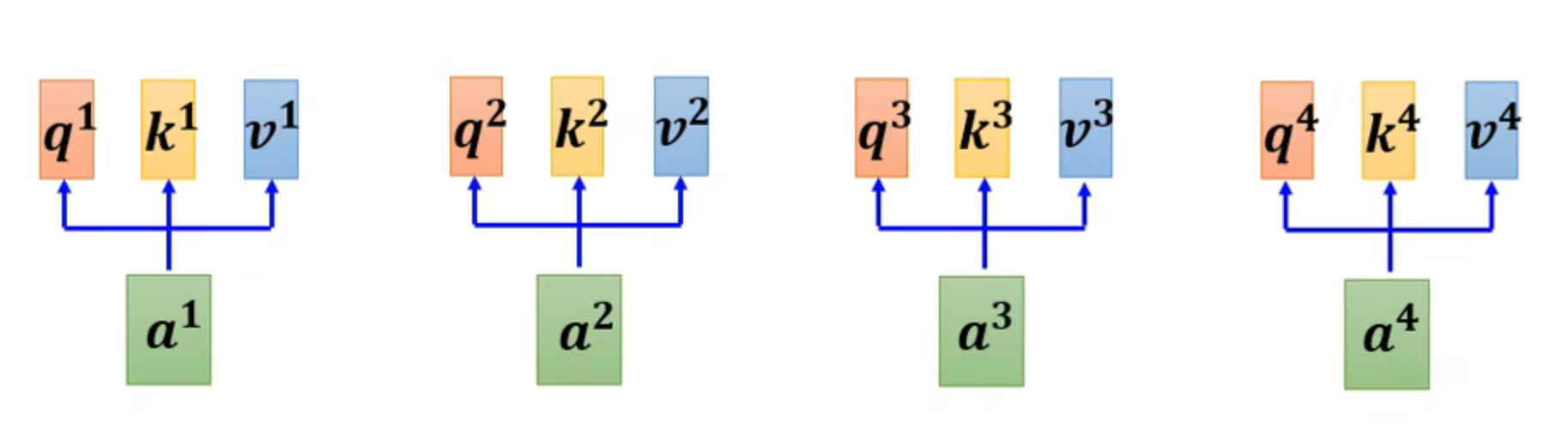 image-20250427121123206
image-20250427121123206- 对输入进行词嵌入,加上位置编码得到a1,a2,a3,a4
- 计算查询向量、键向量、值向量:
Q=q1q2q3q4K=k1k2k3k4V=v1v2v3v4=a1a2a3a4Wq=a1a2a3a4Wk=a1a2a3a4Wv
- 计算attention score
A=α1,1α2,1α3,1α4,1α1,2α2,2α3,2α4,2α1,3α2,3α3,3α4,3α1,4α2,4α3,4α4,4=Q⋅KT=q1q2q3q4⋅[k1k2k3k4]
- 经过dk放缩作softmax,dk为每个key/querey向量的维度大小
输入矩阵 Asoftmax输出矩阵 A′dk1α1,1α2,1α3,1α4,1α1,2α2,2α3,2α4,2α1,3α2,3α3,3α4,3α1,4α2,4α3,4α4,4⇒α1,1′α2,1′α3,1′α4,1′α1,2′α2,2′α3,2′α4,2′α1,3′α2,3′α3,3′α4,3′α1,4′α2,4′α3,4′α4,4′
- 计算与值向量加权求和的值
[b1,b2,b3,b4]=α1,1′α2,1′α3,1′α4,1′α1,2′α2,2′α3,2′α4,2′α1,3′α2,3′α3,3′α4,3′α1,4′α2,4′α3,4′α4,4′⋅v1v2v3v4
即
Attention(Q.K,V)=softmax(dkQKT)V
如下图所示:会使用多的矩阵去作变换,如Wq,1,Wq,2
 image-20250510194255934
image-20250510194255934以四个词,两个头为例,下面来展示计算过程
对于四个词向量ai,aj,am,an,可以用Wq,Wk,Wv先计算出全局查询的查询、键、值向量,Q,K,V
其中:Wq,Wk,Wv为全局权重矩阵
Q=aiajamanWqK=aiajamanWkV=aiajamanWv
!!要注意的是多头拆分也可以直接通过全局矩阵Q,K,V进行分割
Q1=QWq,1Q2=QWq,2K1=KWq,1K2=KWq,2V1=VWq,1V2=VWq,2
Q1=qi,1qj,1qm,1qn,1Q2=qi,2qj,2qm,2qn,2
K1=ki,1kj,1km,1kn,1K2=ki,2kj,2km,2kn,2
V1=vi,1vj,1vm,1vn,1V2=vi,2vj,2vm,2vn,2
head1=softmax(dkQ1K1T)V1head2=softmax(dkQ2K2T)V2
multihead=[head1head2]
output=multihead⋅WO
适用于多向量输入的情形,且输入向量之间是有联系的
因此不能用FC作为训练模型,FC忽略了向量之间的联系,训练效果会很差
工作示例图:
- 自注意力机制考虑了所有输入向量,然后把整个考虑的结果输出成一个向量给到FC进行训练
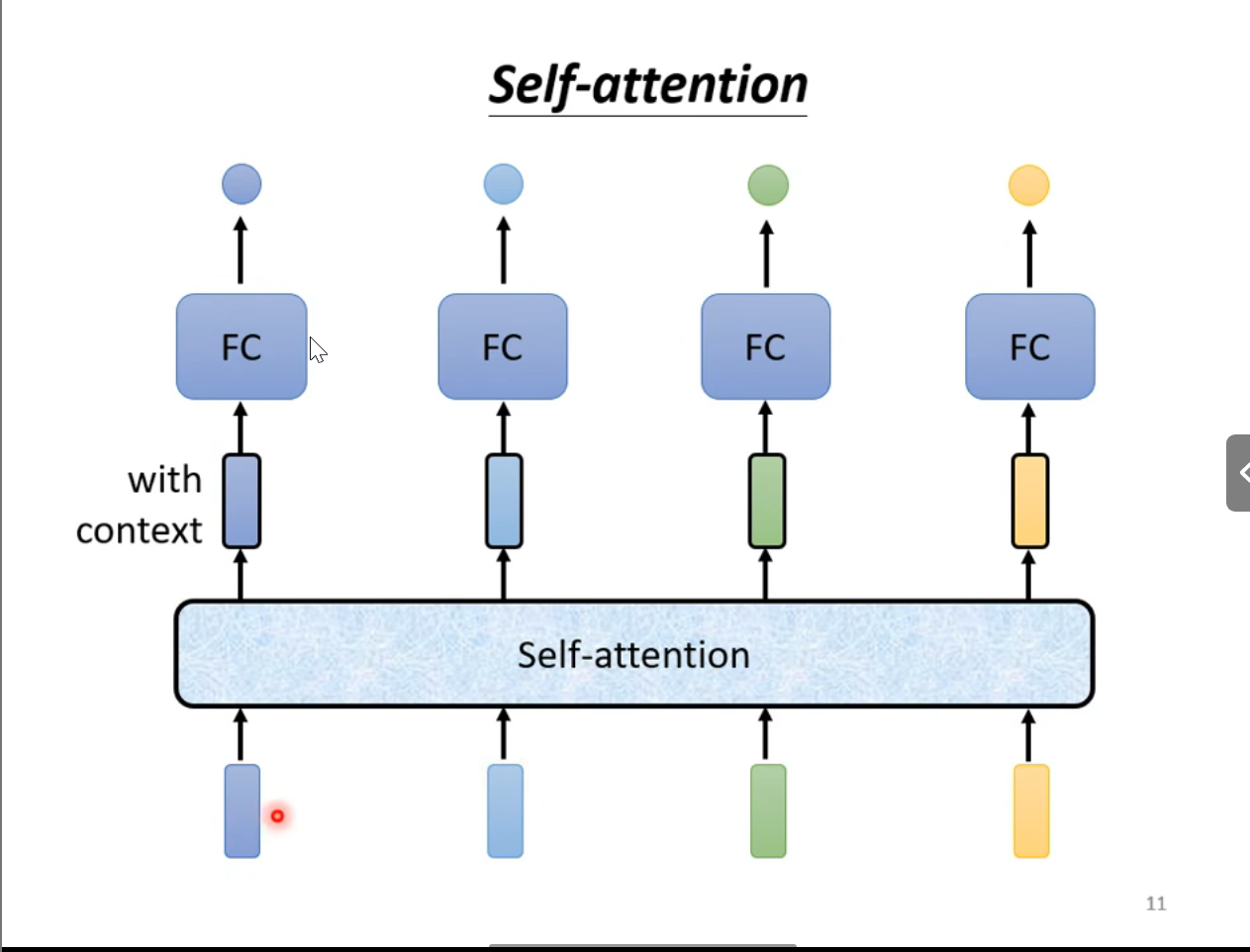 image-20250418130432286
image-20250418130432286基本思想:自注意力允许模型在处理序列数据时,计算序列中每个位置与所有其他位置之间的关联性
三个关键向量:
- 查询向量(Query,Q)
- 键向量(Key,K)
- 值向量(Value,V)
计算步骤:
对输入序列中的每个元素,通过三个不同的权重矩阵生成Q,K,V向量
使用三个不同的权重矩阵进行线性变换:
- Q=X×WQ
- K=X×WK
- V=X×WV
其中WQ,WK,WV是可训练的参数矩阵
计算每个位置的查询向量(Q)与所有位置的键向量(K)的点积,获得attention score(注意力分数)
- dot product本质上是测量两个向量之间相似度的方法。当两个向量方向相似时,点积值较大;方向相反时,点积为负;方向垂直时,点积为零
- 查询向量(Q)相当于**"我想找什么信息"**
- 键向量(K)相当于**"各个位置提供的信息类型"**
- 点积结果表示**"这个位置提供的信息与我需要的匹配程度"**
对注意力分数进行缩放(除以键向量维度的平方根),主要是方式后续的softmax被推入梯度极小的区域,防止梯度消失
应用softmax函数(如归一化RELU也可以),将分数转换为概率分布
用这些概率加权求和所有位置的值向量(V),最后算出来的值会被attention score最高的输入所主导
- 值向量(V)决定位置包含的实际信息内容
- Q-K点积:确定**"我应该关注哪里"**(计算相关性)
- V的加权求和:确定**"我应该提取什么信息"(获取内容)**
要有多个查询向量Q,不同的查询向量负责不同种类的相关性
- 计算ai与其它输入的关联性
- 计算bi,1
- 根据qi,1,ki,1,kj,1计算出bi,1
- 计算bi,2
- 根据qi,2,ki,2,kj,2计算出bi,2
- 计算bi
- 使用bi,1与bi,2再乘上一个权重矩阵得到bi,得到attention score
- 后面的处理与前面类似
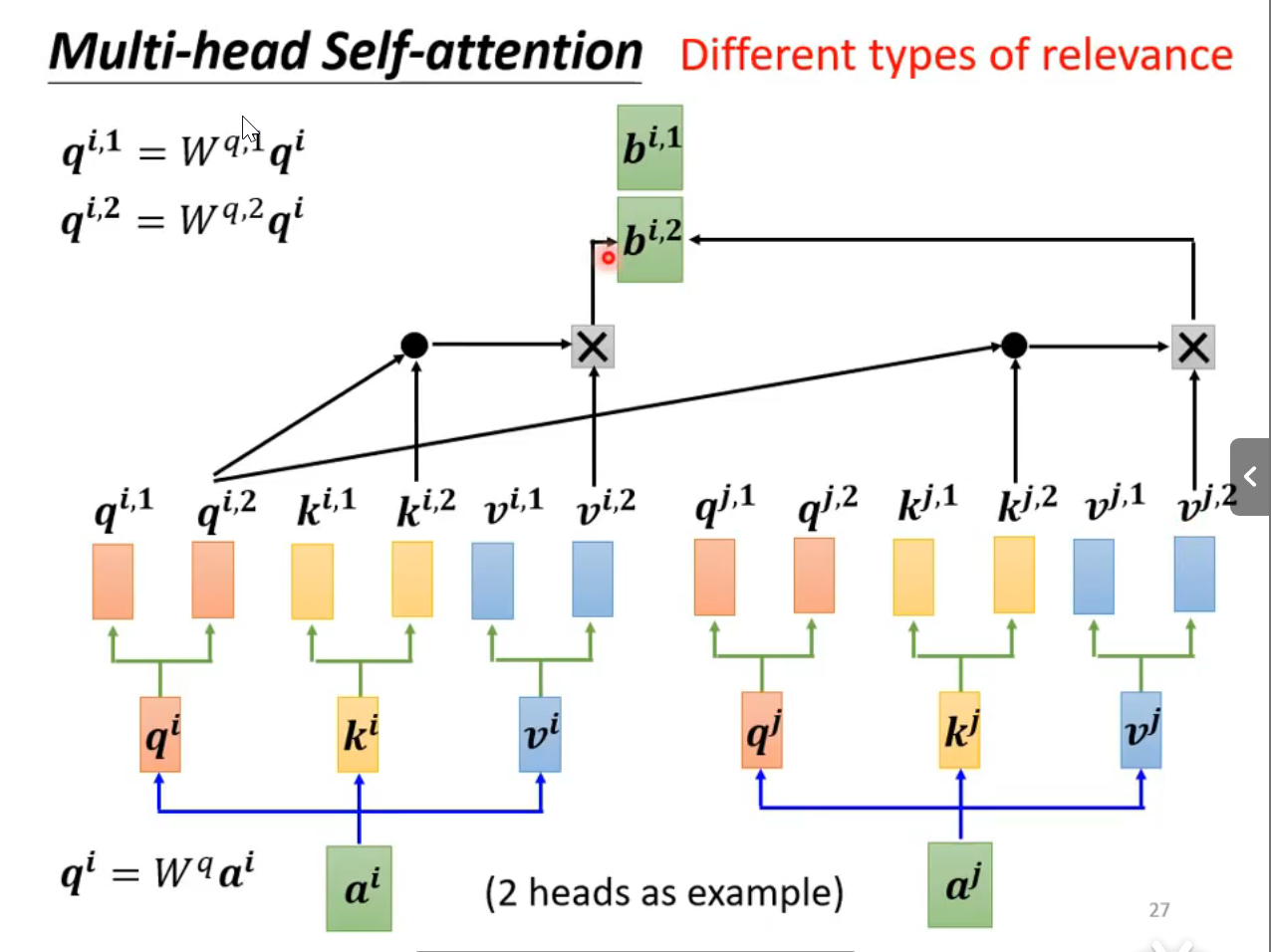 image-20250420112828589
image-20250420112828589自回归模型是一个词一个词生成的,也就是说模型在做推理任务的时候是无法看到后面的词的。
相应地,在训练的过程中,我们会给予模型正确的输出,但是我们并不希望模型看到它还未生成的词,也就是说假设训练数据是句子 "A B C D",模型会一次性看到全部token,但通过掩码限制每个位置只能注意左侧。
自回归掩码(上三角掩码):通常用于K、V矩阵
1111masked111maskedmasked11maskedmaskedmasked1
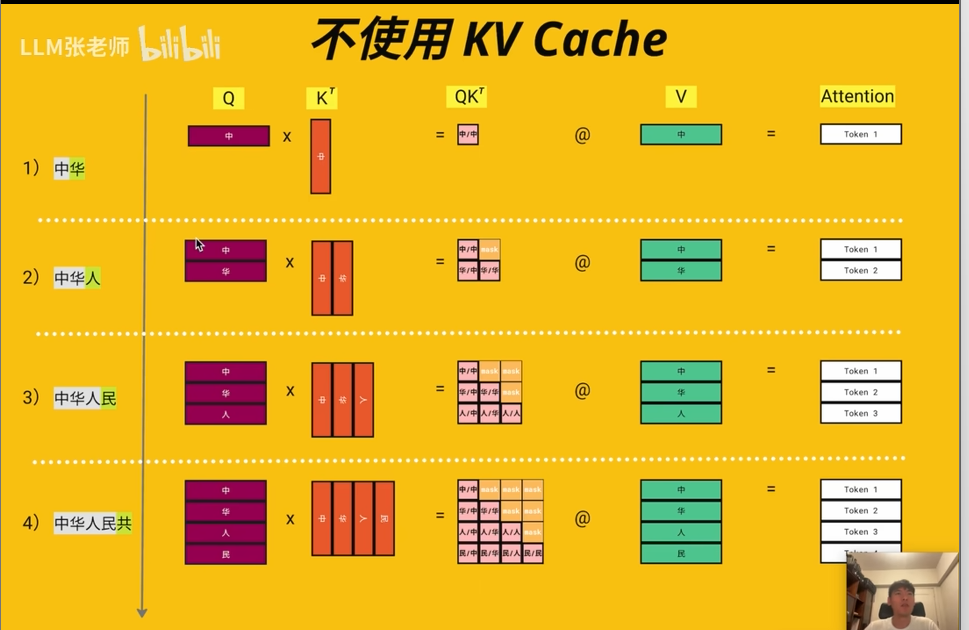 image-20250702191639250
image-20250702191639250传统文本处理尝使用单热编码**(One-Hot Encoding)来表示单词。但是这种表达方式无法捕捉单词之间的语义关系**,不适合用来词的编码
- 因为每个单词表示的向量都是正交的
- 同时维度会非常大,会耗费计算资源
- Self-attention的局限:自注意力机制是"置换不变的",即打乱输入序列顺序后结果不变,这对序列建模是不利的
- 序列顺序的重要性:在语言和其他序列数据中,单词或令牌的顺序包含重要信息,影响意义
绝对位置编码的工作流程
- 生成位置向量**(positional vector),每个位置有唯一**的位置向量
- 把这个位置向量直接加到对应位置的输入词嵌入向量上
Final_embedding = Token_embedding + Positional_encoding
给每个位置分配一个单独的向量
常用:可学习式、三角式
PE(pos,2i)=sin(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/100002i/dmodel)
- pos为绝对位置
- 2i为维度下标,2i≤dmodel
- dmodel为模型维度,也就是每个词或者位置会被编码为dmodel维的向量
- 比如I am a kid
- 绝对位置
- 维度下标(对于am,pos=1)
- i=0
- 第0维:PE(1,0)=sin(1/100000/dmodel)
- 第1维:PE(1,1)=cos(1/100000/dmodel)
- i=1
- 第2维:PE(1,2)=sin(1/100002/dmodel)
- 第3维:PE(1,3)=cos(1/100002/dmodel)
为每个位置分配一个向量,通过一个二维旋转矩阵引入相对位置信息
- 编码因子:wi=10000dmodel2i
- 指数级频率变化
- 在表达式中,pos/wi为频率,而编码因子以10000为底数,不同维度的波长呈现至少级变化,允许位置编码在非常宽的频率范围内分布,因为编码因子可以看作是指数函数(后续给出证明)
- 这种特性允许模型捕捉长距离的和短距离的依赖关系(词和词之间),对于任意长度的序列都适用,有效解决了LSTM里面长序列遗忘的问题
- 平滑频率变化
- 模型需要处理高维特征,dmodel越大,说明wi的增长就越慢,从而导致100002i/dmodel增长缓慢,因而相对于位置pos变化,$ pos/10000^{2i/d_{model}}$变化得更慢,导致频率变化变慢
- 这种情况可以导致相邻位置编码差异较小,让模型能够捕捉到位置连续性和顺序性
位置(pos+Δ)处的编码[PE(pos+Δ,2i)PE(pos+Δ,2i+1)]=相对位置信息[cos(Δθi)−sin(Δθi)sin(Δθi)cos(Δθi)]位置pos处的编码[PE(pos,2i)PE(pos,2i+1)]
其中:Δ为绝对位置之差,θi=10000dmodel2i1
而
顺时针旋转Δθi[cos(Δθi)−sin(Δθi)sin(Δθi)cos(Δθi)]
是一个旋转矩阵,表示顺时针旋转Δθi (与具体的位置pos无关)
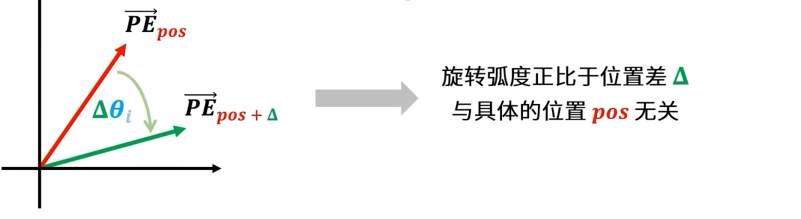 image-20250701224305593
image-20250701224305593下面我们来证明一下
[PE(pos+Δ,2i)PE(pos+Δ,2i+1)]=[sin((pos+Δ)⋅θi)cos((pos+Δ)⋅θi)]=[sin(pos⋅θi)cos(Δ⋅θi)+cos(pos⋅θi)sin(Δ⋅θi)cos(pos⋅θi)cos(Δ⋅θi)−sin(pos⋅θi)sin(Δ⋅θi)]=[cos(Δθi)−sin(Δθi)sin(Δθi)cos(Δθi)][sin(pos⋅θi)cos(pos⋅θi)]=[cos(Δθi)−sin(Δθi)sin(Δθi)cos(Δθi)][PE(pos,2i)PE(pos,2i+1)]
已知:
wiθi=100002i/dmodel=pos/100002i/dmodel=pos/wi
- i小:wi小,频率高,对应词向量低维度,θi对pos变化敏感,捕捉短距离依赖
- i大:wi大,频率低,对应词向量高维度,θi对pos变化不敏感,对于长序列的词,位置编码的值不会变成0,例如Δpos=1000,100001000=0.1,能捕捉长距离依赖
- 如果wi为10000,sin(pos/10000)需pos变化20000π才重复周期,出现相同编码值,混淆文档开头和结尾的词,但是在日常使用并不会出现如此长序列的词(这种方式也决定了它的使用上限)
相对位置编码来源于绝对位置编码,我们先来推导下绝对位置编码下Q和K的表达形式
qi=Wq(xi+pi)kj=Wk(xj+pj)
二者做内积
qiTkj=(xi+pi)TWqTWk(xj+pj)=输入向量内积xiTWqTWkxj+输入-位置交互项xiTWqTWkpj+piTWqTWkxj+位置编码内积piTWqTWkpj
假设位置信息和输入信息相互独立,上式可化成
qiTkj=xiTWqTWkxj+相对位置项piTWqTWkpj=xiTWqTWkxj+相对位置项βi−j
而βi−j是偏置项,也就是相对位置编码,在多头注意力中,每个注意力头headh都会分配一组偏置项βi−jh(why??/)
引入分桶处理的思想:不同的位置差按照大小会被分配到不同的桶内
写代码再细学
直接在QK内积上加上一个不用训练的偏置项,这个偏置项是位置差矩阵乘以m
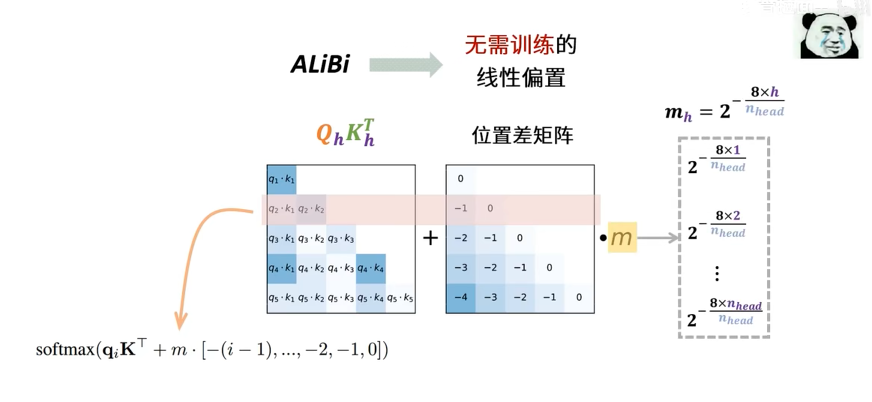 image-20250702192315616
image-20250702192315616其中:m是每个注意力头的斜率,mh=2−nhead8×h,nhead为多头注意力的头数
m=2−nhead8×12−nhead8×2⋯2−nhead8×nhead
位置差矩阵是一个下三角矩阵,位置差矩阵Dij=−(i−j)
最后效果是
softmax(qiKT+m⋅[−(i−1),…,−2,−1,0])
结合了旋转位置编码和相对位置编码,对每个Q和K左乘一个旋转矩阵
在正常的注意力分数计算过程当中,我们是这么计算的
Attention_score=qm⋅knT
但是为了融入相对位置信息,我们让q和k分别乘上一个旋转矩阵
qrot=qm⋅Rmkrot=kn⋅Rn
所以:
qrot⋅krot=qmRmRnTknT=qmRmR−nknT=qmRm−nknT
可见其将位置差信息融入Q,K矩阵,同时由于RoPE的特性,模型可以外推自己的上下文能力并且还保持一定精度
旋转矩阵周期性
对于过大的相对位置模型可能从未见过,但是由于旋转矩阵具有周期性,可以使这个相对位置落在训练过的范围内,从而增强泛化能力
线性位置差
无论绝对位置 m,n 多大,注意力分数仅依赖相对位置m−n
旋转矩阵的构造
- 对于维度为d的向量,RoPE将向量分成d/2组,每组应用一个二维旋转矩阵,d一般都是偶数
Rθ,m=cosmθ1sinmθ100⋮−sinmθ1cosmθ100⋮00cosmθ2sinmθ2⋮⋯⋯−sinmθ2cosmθ2⋱0000⋮
[xi′xi+1′]=[cosmθisinmθi−sinmθicosmθi][xixi+1]
已知位置差(m−n)的旋转矩阵:
这里θi=10000dmodel2i1
Rm−n=[cos((m−n)θi)−sin((m−n)θi)sin((m−n)θi)cos((m−n)θi)]
可以分解
RnTRm=Rm−n
由旋转矩阵性质可知:
R−m=RmT
再以内积形式呈现
(Rnq)TRmk=qTRm−nk
所以有
qnrot=Rnqkmrot=Rmk
可见其将位置差信息融入Q,K矩阵
- 主要应用于推理阶段
- 只存在于解码器中
- 目的是为了加速Q,K,V相乘速度
- 但也会加大内存占用
出现这个技术的原因是在自回归模型中,模型生成的是一个接一个的token。模型每次都要把预测输出的文字序列重新丢到模型里面计算,那么就要重新计算K,V,浪费计算资源。
比如:
如果不使用KV Cache进行缓存,模型就要重复计算“我是”这两个词的K,V
不适用KV Cache
image-20250702191639250使用KV Cache
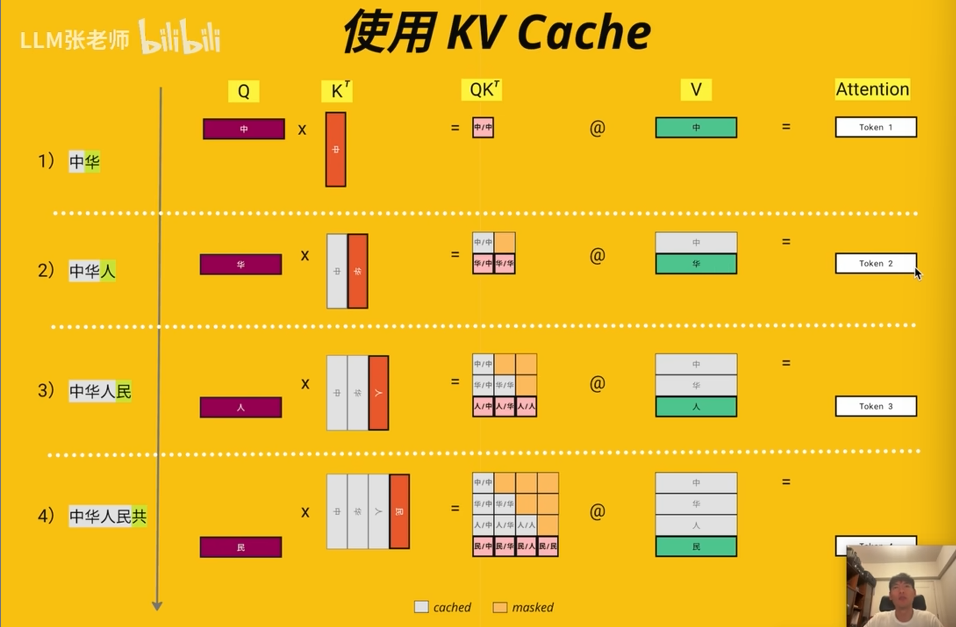 image-20250702191137599
image-20250702191137599Pre-Norm(前归一化)和**Post-Norm(后归一化)**是Transformer模型中两种不同的归一化策略。他们的主要区别在于LN(Layer Normalization)的位置不同。
- 前归一化:在自注意力模块或者前馈网络之前进行层归一化,这种结构在训练时更容易且较为稳定
- 后归一化:在自注意力模块或者前馈网络之后进行层归一化。原始的Transformer使用的是这个,可以帮助稳定梯度,但需要更加谨慎地调节参数,如学习率预热(warm-up)。
- 目前比较主流的方法是前归一化,因为其训练起来比较稳定