本页PDF
基于CBOW或者skip-gram来计算词向量矩阵,主要目的是为了得到词向量
中心词和上下文词用一个窗口来维护
词嵌入向量:v=W×onehot(v)
其中:W是Word2Vec中的权重输入矩阵
核心:用上下文词预测中心词
输入是上下文文本单词的one-hot向量,通过线性变换压缩成一个单词向量,再通过一次线性变换得到一个单词得分表,最后经过多分类得到要预测的单词。
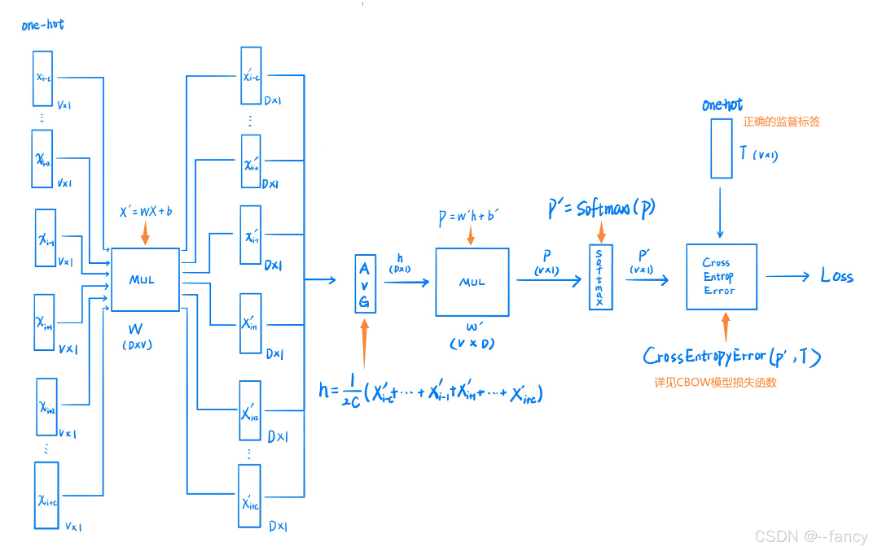 image-20250705224627824
image-20250705224627824上下文(输入)词的多少取决于窗口大小C,因此输入为
X=(xi−c,xi−c+1,…,xi−1,xi+1…,xi+c)∈RV×2C
其中,xi为目标单词,xi∈RV×1
将目标单词xi的单热编码与隐藏层的输入权重W相乘再加上偏置b∈RD×1得到xj′,即Xj′=WXj+b,写成矩阵形式
X′=WX+b
其中
X=[xi−c,xi−c+1,…,xi−1,xi+1…,xi+c]X′=[xi−c′,xi−c+1′,…,xi−1′,xi+1′…,xi+c′]
将输入层得到的所有Xj′进行加权平均得到h
h=j=i−C,j=i∑i+C2C1(xi−c′+xi−c+1′+xi−1′+xi+1′+xi+c′)
将得到的h作线性变换得到每个单词得分的向量P,P=(P1,P2,…,PV)T,Pi∈R表示为位置索引为i处的单词得分
P=W′h+b′
将输出层得到的得分用Softmax处理为概率P′,P′=(p1′,p2′,…,pV′),pi′表示位置索引为i处的单词概率
pi′=softmax(pi)=∑k=1Vexp(pk)exp(pi)
模型的输出是在P′中取出最大概率对应位置的值设为1,其他位置设为0,得到一个单热编码。这个单热编码对应的词就是模型作为预测结果的词。
用的是交叉熵损失(Cross Entropy),交叉熵损失的输入是Softmax层计算得到的概率向量P′和正确的监督标签T,其中P′=(P1′,P2′,…,PV′)T,正确的监督标签T=(t1,t2,…,tV)就是正确答案单词的单热编码。
Loss=−i=1∑Vtilog(Pi′)
核心:用中心词预测上下文词
模型输入时目标单词的单热编码,通过线性变换形成预测上下文单词的向量,再通过一次线性变换得到每一个上下文单词的得分表,最后经过多分类得到要预测的上下文单词。
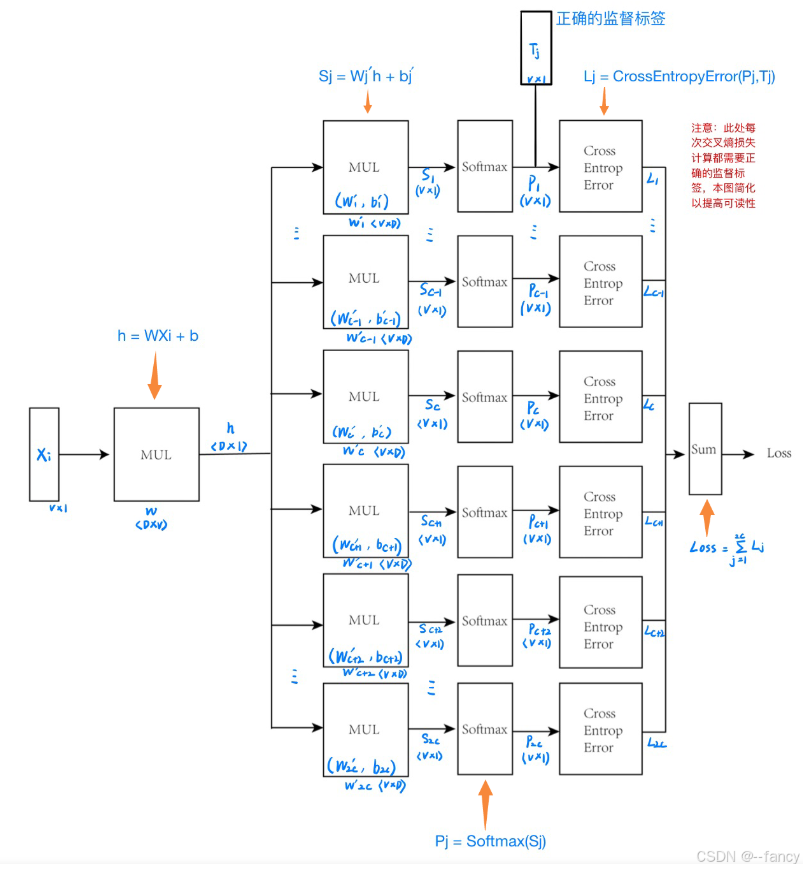 image-20250705224657637
image-20250705224657637将目标词表示为单热编码,作为模型输入 xi∈RV×1,i 表示目标单词所在位置。
将目标词的单热编码 xi∈RV×1 作线性变换得到隐藏层向量h
h=Wxi+b
将得到的h与隐藏层的权重输出矩阵Wj′相乘再加上偏置项bj′得到多个上下文单词得分的向量Sj∈RV×1,S=(S1,S2,…,S2C)T。
Sj=Wj′h+bj′
将输出层得到的得分Sj用softmax处理为概率Pj,Pj=(Pj(0),Pj(1),…,Pj(V−1))T
Pj(k)=Softmax(Sj)=∑l=0V−1exp(Sj(l))exp(Sj(k))
模型输出是在P中取出最大概率对应位置的值设为1,其他设为0,得到一个单热编码,这个单热编码对应的词就是预测上下文单词的结果。
使用交叉熵损失(Cross Entropy)进行计算,其输入是概率向量Pj(k),和正确的监督标签T,其中Pj=(P1,P2,…,P2C),正确的监督标签Tj=[tj(1),tj(2),…,tj(V)]是正确答案单词的单热编码。
Lj=−k=1∑Vtklog(Pj(k))Loss=j=1∑2CLj
正常使用word2vec模型,我们是要预测V个单词出现的概率,但是语料库十分巨大,这么做肯定不现实,因此我们可以使用Huffman树来加速,把运算次数压缩到logV。
基本思想:将词典中的每个词按照词频大小构建出一颗Huffman树,词频大的词处于浅层,词频小的词处于深层。
- 叶子节点都是词
- 非叶子节点具有要学习的参数,是一个二分类器,全部都接受相同的输入(上下文向量)
如图所示:
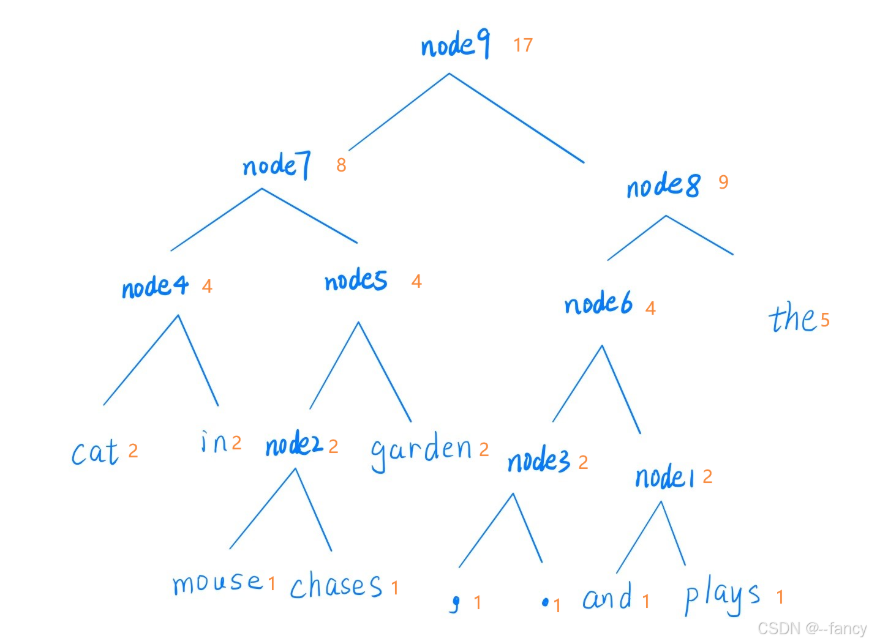 image-20250705162047281
image-20250705162047281计算概率的步骤:
- 已知每个非叶子节点具有网络参数,可以用网络参数算出并使用softmax算出来一个概率值P,称为正向概率
- 因为哈夫曼树是二叉树,知道一个分支的概率P,我们就可以算出另外一个分支的概率为1−P
- 按上述步骤不断进行,我们就可以算出每个非叶子节点每个分支的概率
- 根据上述算出来的值,可以通过概率连乘算出每个词的概率
正样本:真实有效的上下文本对,(中心词,上下文词)
负样本:从词汇表中随机选择一些不相关的词作为负样本。通过负样本来训练模型,使模型学习到区分正样本和负样本的能力
基本思想:通过从词汇表中随机选择一些“负样本”来代替计算所有可能的上下文词,从而大幅度降低计算复杂度。将多分类问题转化为二分类问题,让模型对正样本预测的概率逼近1,对负样本预测的概率逼近0。
这里重点讲一下损失函数,因为前面的流程基本都差不多
正样本损失
我们可以知道T1是正确的标签,T1=(t1,t2,…,tV)T,P是每个单词对应的概率,P=(P1,P2,…,PV),在这里进行优化。在T中,只有正确索引位置为1,进行损失函数计算时,只保留正确索引位置单词的得分概率,因此我们将得分向量中正确的得分直接取出,即S1=(θ1h)TT1
随后直接将得分转换为概率,此处是二分类问题,用sigmoid函数,最后应用于Cross Entropy
P1=σ(S1)=σ((θ1h)TT1)=1+e−((θ1h+b1′)TT1)1Loss+=−log(P1)=−log(1+e−((θ1h+b1′)TT1)1)
负样本损失
首先要进行负采样,按照词频给出每个单词的概率分布
f(w)=∑i=1V[count(i)]43[count(w)]43
其中,count(index)计算索引位置为index位置单词的词频,w表示目标单词的索引,V为词汇表的大小。
接着按照概率分布进行采样,若抽取到正例则重新采样。数据量大,负样本个数k通常为5,数据量小,负样本个数通常为5~20个。
对于采样出的负样本, 我们计算对应的得分之后将其取负号再使用Sigmoid函数,然后使用原来计算正样本的方式进行计算。
我们将负样本权重输出矩阵θ0与隐藏层的向量h相乘得到单词得分向量,随后依次去除每个负样本对于索引位置单词的得分然后取负号
S0,i=−(θ0h+b0′)TT0,i
其中,T0,i为负样本对应的标签,然后使用Sigmoid函数转换为概率
P1=σ(S0,i)
使用交叉熵计算损失
Loss−=i=1∑klog(P0,i)
最后将Loss+与Loss−相加得到总的损失Loss
Loss=Loss−+Loss+